How Crusoe's root cause analysis drove a 70% reduction in NIXL's memory footprint
When NIXL workloads started triggering host OOM kills on NVIDIA HGX H200 and HGX B200 instances, Crusoe traced the root cause to firmware-page fan-out across all 8 NICs — driving a fix that cuts host memory overhead by up to 75%.


A few weeks ago, one of our customers reported something odd on their GPU fleet. Their NVIDIA HGX H200 and HGX B200 instances, running NVIDIA Inference Xfer Library (NIXL) workloads, were being killed by the host OOM killer. The GPUs weren't the issue. HBM usage was well within limits, utilization looked healthy, and there was nothing unusual in the NVIDIA CUDA allocator. The host itself, a machine with plenty of RAM, kept running out of memory.
This is a walkthrough of how we traced that back to NIXL's memory registration pattern, why the first fix we found only got us halfway, what the durable mitigation looks like, and how our findings drove an upstream fix that cuts NIXL's host memory footprint by ~70%.
The setup
Our virtualization stack at Crusoe uses Linux KVM with Cloud Hypervisor and VFIO passthrough. Each NVIDIA GPU VM instance is allocated whole GPUs via VFIO passthrough and ConnectX HCA virtual functions via SR-IOV: the VFs are exposed to the guest, while the physical functions and firmware-page accounting stay on the host.
A quick primer on the hardware. Our GPU hosts run 8 NVIDIA ConnectX InfiniBand NICs (HCAs), one per GPU. When a workload wants to move data between GPUs across hosts, it registers GPU buffers with these NICs so the firmware knows how to DMA to and from them. Each registration consumes a small amount of pinned host memory that the kernel cannot reclaim. The mlx5 driver exposes this through a counter at /sys/kernel/debug/mlx5/<dev>/pages/fw_pages_total. On a healthy workload running NVIDIA Collective Communications Library (NCCL), that counter sits at a modest steady state.
NIXL is a newer data transfer library from NVIDIA, built on top of UCX. It targets modern AI inference patterns like disaggregated serving, KV-cache transfer between prefill and decode workers, and general GPU-to-GPU RDMA. NIXL version 1.0.0 was shipped about a month before this investigation started.
What we saw
The OOMs weren't random. They correlated with NIXL-heavy workloads. MemAvailable in /proc/meminfo was dropping to zero. Buffer and page cache were getting fully reclaimed. Swap was filling up. Then the kernel started killing processes.
When we checked fw_pages_total on an affected host, the numbers were far higher than anything we'd seen on comparable NCCL workloads. For a guest VM registering roughly 75 GB per GPU through NIXL, each of the 8 NICs on the host reported over a million firmware pages. That worked out to roughly 34 GiB of host memory consumed by firmware-level registrations alone, before anything else on the box.
The question became: why is NIXL driving fw_pages to these levels?
Reproducing it in isolation
To properly diagnose and address this issue, we wanted a clean reproduction of this issue. We built one on an in-house HGX B200 host with 8 ConnectX-7 NICs and a VM with 8 NVIDIA Blackwell GPUs passed through. Inside the guest VM, the following script allocates a large tensor on each GPU, hands it to NIXL for registration, and pauses so we can read the host-side counters. We subsequently confirmed the same behavior on HGX H200 and HGX B200 hosts. The specific numbers below come from the HGX B200 setup, but the registration pattern is consistent across generations.
## This script is run inside the HGX B200 guest VM.
import torch
import nixl
agent = nixl.nixl_agent("test")
tensors = []
for i in range(8):
# 40 GB per GPU, 320 GB total
t = torch.zeros(10240 * 1024 * 1024, dtype=torch.float32, device=f"cuda:{i}")
tensors.append(t)
input("BEFORE register, press Enter...")
regs = [agent.register_memory(t) for t in tensors]
input("AFTER register, press Enter...")On the host, two watch loops:
watch -n 2 'for d in /sys/kernel/debug/mlx5/*/; do cat ${d}pages/fw_pages_total; done'
watch -n 2 'grep -E "MemAvailable|MemFree" /proc/meminfo'At 40 GB per GPU, fw_pages per NIC climbed to around 525,000 and MemAvailable settled at roughly 5 GiB. At 75 GB per GPU, fw_pages jumped to 1.1 million per NIC, MemAvailable hit zero, and the host OOMed. No transfers, no traffic. Just the act of registering memory was enough to exhaust the host.
Finding the immediate trigger
NIXL inherits a lot of its behavior from UCX. UCX has many config options, most of which default to reasonable values for general HPC workloads. One of them is IB_PCI_RELAXED_ORDERING, which controls whether the NIC creates a relaxed-ordering memory region alongside the normal one. Relaxed ordering lets the NIC reorder PCIe transactions, which can help throughput on some hardware. The cost is that the firmware tracks two sets of page tables per registration instead of one.
UCX defaults this to auto, meaning UCX picks based on what the hardware reports. On our hardware, auto resolves to off.
NIXL overrides this to try. The override lives in src/plugins/ucx/ucx_utils.cpp:
config.modify("IB_PCI_RELAXED_ORDERING", "try");With try, UCX creates relaxed-ordering regions if the hardware supports them. Our hardware does, so every registration produces two regions instead of one. That's a 2x multiplier on firmware pages, applied unconditionally to every buffer NIXL registers.
To verify, we re-ran the experiment with UCX_IB_PCI_RELAXED_ORDERING=auto set in the VM's environment. NIXL's config logic checks for a pre-set env var before applying its own value, so this effectively undoes the override without any code changes:
The 2x ratio held cleanly at every scale. Setting the env var to auto roughly doubled the GPU memory we could register before hitting OOM.
At this point we had a satisfying-looking answer. A setting was flipped, you flip it back, the problem is halved. We nearly stopped there.
The part that kept bothering us
Two things nagged. First, fw_pages with auto was still climbing linearly with registered GPU memory. The slope was shallower, but there was no ceiling. Second, when we pushed the workload further, auto also OOMed, just at a higher threshold (around 144 GB per GPU instead of 75 GB).

So try vs auto was a 2x multiplier. But on top of what baseline?
We went back to NIXL's source and looked at what happens when a user registers a buffer. NIXL registers it on every HCA on the host. On our hosts, that means one user-visible buffer produces 8 firmware-level registrations, one per NIC. NCCL, by contrast, registers each buffer on a single affinity NIC, producing one registration per buffer.
Lining up the multipliers:
- NCCL: 1 registration per buffer
- NIXL with
auto: 8 registrations per buffer (one per HCA) - NIXL with
try(default): 16 registrations per buffer (a normal MR plus a relaxed-ordering MR, per HCA)
The fan-out makes the difference obvious:
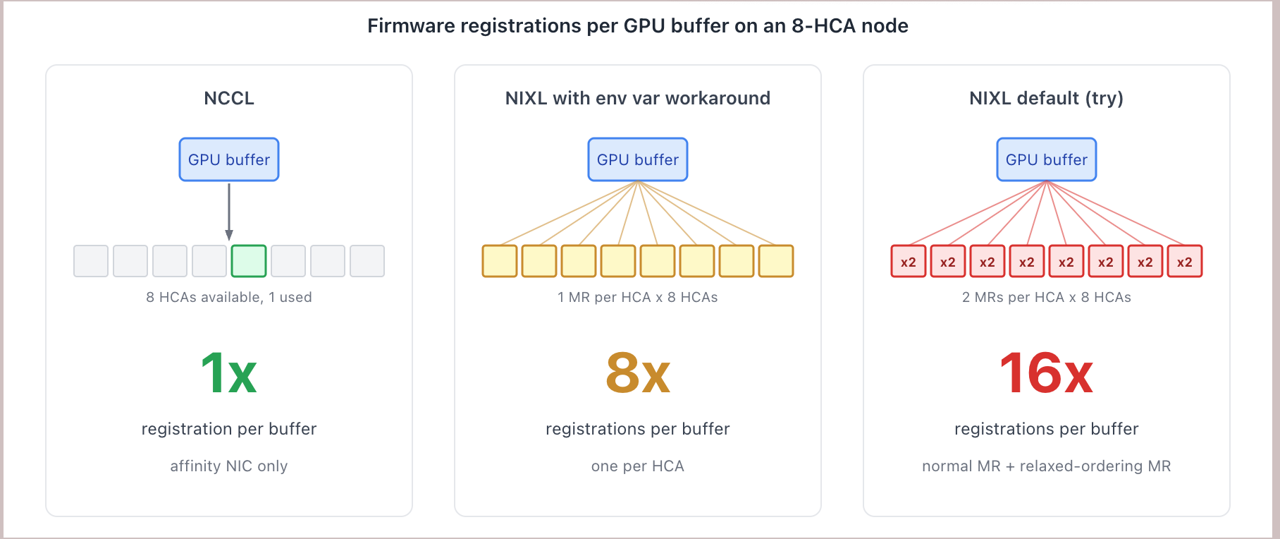
That reframed the problem. auto brings you from 16 down to 8. The 8x floor is a property of NIXL's default registration pattern in this configuration, not something the user can configure via env vars.
There is a reasonable rationale for registering on every HCA. It lets NIXL pick the best path per transfer without a late-binding penalty, which matters for latency-sensitive workloads. At low registration volumes the overhead is negligible. At 75+ GB registered per GPU across 8 GPUs, it becomes 16x the host memory footprint NCCL would see for the same working set, and the host can't absorb it.
A note on UCX_IB_PCI_RELAXED_ORDERING
One knob worth mentioning, with caveats. Setting UCX_IB_PCI_RELAXED_ORDERING=auto in the guest environment before NIXL starts drops the per-buffer multiplier from 16x to 8x, because NIXL checks for a pre-set UCX env var before applying its own override:
export UCX_IB_PCI_RELAXED_ORDERING=auto
This roughly doubles the GPU memory that can be registered before OOM on the host. However, try vs auto is a PCIe ordering choice, and relaxed ordering can improve RDMA throughput on some hardware. Flipping it to auto removes the relaxed-ordering MRs, which may reduce transfer throughput depending on the workload. Whether that tradeoff is worth it depends on the specific workload and how close it is running to the host memory ceiling. We'd recommend benchmarking before adopting it as a permanent setting.
Mitigation
The mitigations we've deployed live on the host and don't require changes inside the guest.
First, reconfiguring the memory split between host and guest buys headroom. Reserving more memory for the host (and correspondingly less for the guest) raises the ceiling before firmware page growth pushes MemAvailable to zero. This doesn't stop the growth, but it gives operators more room to run workloads at production scale without tripping the OOM killer. The right split depends on the workload's registration profile and the host's total memory, so this is tuned per deployment rather than applied uniformly.
Second, the durable protection is a per-VF cap on firmware pages, configured on the host via VHCA_ICM_CTRL. This puts a ceiling on the firmware pages any single VM can drive on the host through its RDMA memory registrations, regardless of what the workload is doing or how the library is configured. It's enforced on the host, so it holds regardless of what the guest does.
We worked with NVIDIA engineers, who reproduced the memory usage pattern internally, confirming the NIXL behavior.
The upstream fix
While we were working through the mitigations above, our findings also triggered a parallel discussion inside the NVIDIA NIXL and Mellanox engineering teams. We were also the first to surface this problem to NVIDIA. The outcome landed as NIXL PR #1637 (targeted for NIXL 1.2), paired with UCX 1.21 (PRs #11422 and #11453).
The fix introduces a new UCX parameter, UCX_MAX_HCA_PER_GPU, with three modes: inf (the previous behavior, register on every reachable HCA), auto (register only on the topologically closest HCAs, where "closest" is determined by GPU-to-HCA latency and bandwidth), or an explicit <N> to cap the count. The policy applies per-buffer at registration time and only to GPU memory; non-network domains like cuda_copy are unaffected.
NIXL's PR #1637 sets UCX_MAX_HCA_PER_GPU=auto automatically when it detects UCX 1.21 or newer, so users get the benefit without configuration. That shrinks the per-HCA fan-out from 8 down to the topologically closest subset. This is consistent with the 71% to 75% savings shown in the results below.
We validated the fix on Crusoe hardware using the steps described earlier. Across two workload sizes per platform, the savings scaled linearly with registration size, and per-NIC fw_pages counts agreed with host MemAvailable deltas to within 1 GiB.
HGX H100 / ConnectX-7
HGX B200 / ConnectX-7
The fix requires no kernel, driver, or firmware changes. To pick it up, workloads need both:
- NIXL v1.2.0 or newer.
- UCX v1.21.0-rc1 or newer.
Concluding Thoughts
In virtualized environments, guest workloads can drive host-side resource consumption the guest itself can't see. mlx5 firmware pages are one such resource: a guest's RDMA registrations consume them on the host, so both monitoring and protection on the host are important. You have to be looking at kernel counters like fw_pages_total or watching MemAvailable drift toward zero to see what's happening.
NIXL is evolving fast, and what started as a customer-reported OOM ended as an upstream fix that benefits every multi-HCA deployment. Thanks to the NVIDIA engineering team for their responsiveness and for landing these fixes in the upstream NIXL and UCX repositories. This story showed us the value of close collaboration in shaping the upstream community around NIXL. Crusoe and NVIDIA will continue to co-design a platform purpose-built for accelerated computing to fuel the next wave of AI innovation.
.png)