Crusoe MemoryAlloy technology: Reinventing KV caching for cluster-scale inference
Technical deep dive into Crusoe's MemoryAlloy technology: A distributed KV cache and gateway architecture that achieves 9.9x faster TTFT and 5x higher throughput for multi-node LLM inference.



Modern LLM serving is dominated by two constraints: GPU memory and compute. A big part of that pressure comes from the prefill phase, the stage where the model processes the entire prompt before producing the first token. This step quickly becomes compute-bound, making long prompts the primary driver of latency and inflating queue times, creating head-of-line blocking for other user requests.
Many real-world workloads contain highly repetitive structure. Chat sessions keep appending turns on top of the same prefix. Long-document question answering repeatedly references shared context. Agentic workloads cycle over large, stable prompts. Most LLM engines maintain only a relatively small prefix cache, known as the KV cache, which can deliver significant speedups when shared prefixes are already computed. But because this cache resides in GPU memory, it is small, and in realistic workloads useful prefixes are frequently evicted and need to be recomputed during prefill.
Scaling this caching layer to larger memory capacity holds enormous potential: more users served at lower latency, better throughput, and less wasted compute. The typical industry answer is to add a second-tier local cache on each node to increase hit rates. In practice, this falls apart in real inference clusters where many LLM engines run across multiple machines. Local caches fragment by node, cannot be reused across instances, and disappear on pod restarts. At cluster scale, the efficiency gains drop off fast.
Crusoe’s inference engine takes a different approach by addressing this pain directly: treat KV as a first-class, cluster-wide memory object. Our system introduces MemoryAlloy technology, a unified memory plane independent of any single model or runtime that persists and shares KV segments across nodes with the lowest latency achievable on the underlying hardware. On top of this layer, a lightweight KV-aware gateway routes requests to the instance most likely to achieve a cache hit while also performing load balancing using TTFT (Time-to-First-Token) estimation. This enables efficient query distribution, removes queue bottlenecks, and reduces latency across the entire cluster.
This architecture yields:
- Up to 9.9× faster TTFT than vLLM in real multi-node production workloads.
- Over 5× higher throughput (tokens/sec) than vLLM in live multi-node deployments, scaling linearly with additional nodes through our distributed cluster-wide cache. This higher throughput directly reduces per-token cost, as each compute unit produces significantly more tokens for the same hardware budget.
- Cross-node cache hits that perform nearly as fast as local hits, delivering near roof-line GPU cache-hit performance even when data is fetched from remote nodes.
This post marks our first deep dive into Crusoe’s managed AI inference stack, where we shed light on our distributed KV cache solution (MemoryAlloy technology) and our gateway, the two core components that power this architecture. Throughout this blog, we’ll explore how these systems work together to accelerate inference and present the benchmarks that demonstrate their impact.
Core components
Cluster-wide MemoryAlloy technology
Crusoe’s MemoryAlloy technology layer is a distributed memory fabric that decouples data such as KV-cache segments from individual model processes and exposes them as a shared resource across the entire cluster. Each node runs its own unified memory (UM) service responsible for managing local CPU and GPU memory, all UM services use a lightweight Nexus server (a custom component) as a discovery mechanism to bootstrap each peer-to-peer connection. After discovery, the cluster forms a full peer-to-peer network in which buffers created on one node can be accessed or transferred by any other node at maximal speed.
MemoryAlloy technology provides extremely low-overhead access to data for applications running on GPU Clusters. For data that resides within the MemoryAlloy technology on a local node - applications such as vLLM receive direct handles to UM-managed memory using NVIDIA CUDA or ROCm IPC for GPU buffers and shared memory handles for CPU buffers, allowing the application to operate on the data directly without extra copies. When transferring data between different devices or nodes the system automatically selects the highest-bandwidth transport available; Using proprietary algorithms and all possible data paths such as NVIDIA NVLink™ or PCIe on NVIDIA platforms, and PCIe or Infinity Fabric on AMD platforms, also taking into account NUMA alignment and PCIe/Network topology.
Performance and data paths
High-performance multi-rail sharding
Standard data transfer methods face inherent hardware limitations: When dealing with KV cache offloading, a lot of the data transfer is from DRAM (host memory) to HBM (device memory). Whether locally or from remote. An NVIDIA H100 Host-to-Device PCIe bidirectional connection offers a theoretical bandwidth of approximately 64 GB/s to a single GPU (with practical frameworks like PyTorch typically achieving ~50 GB/s), while a single NVIDIA ConnectX-7 NIC is theoretically limited to ~46 GB/s using GPUDirect (from remote DRAM or HBM). Our MemoryAlloy technology transcends these individual bottlenecks by employing a proprietary sharding algorithm that aggregates bandwidth across the entire possible data paths.
Local Host-to-Device Transfers: In local scenarios, the MemoryAlloy technology overcomes the limitations of a single PCIe link by distributing buffer partitions across the PCIe lanes of the entire node simultaneously. Rather than queuing data through a single device connection, the Send Graph feature stages fragments across the aggregate PCIe bandwidth of all GPUs within the host. These fragments are then effectively funneled to the target destination via high-speed NVLink or AMD xGMI, converting the full PCIe throughput of the node into usable bandwidth for a single GPU.
Remote DRAM-to-GPU Transfers: For remote transfers, the system employs a multi-rail architecture that engages all available MLX network adapters in parallel. By stripping data across multiple network rails, the MemoryAlloy technology saturates the aggregate network capacity rather than being capped by a single NIC. As with local transfers, these fragments arrive at remote GPUs which are adjacent to the desired destination GPU and then are asynchronously united at the destination via NVLink or AMD xGMI. For example, sending from DRAM on node A to GPU-0 on remote node B, might use all NICs and stage buffer fragments on GPU-1, GPU-2, … , GPU-8 and then transfer those to GPU-0 asynchronously.
Performance Impact & TP Optimization: By leveraging these aggregate pathways, the system achieves steady-state throughput of approximately 80 to 130 GB/s when targeting a single GPU, effectively exceeding the capacity of any single physical link (~46GB/s from remote, ~64GB/s locally). Furthermore, when transferring data to all eight GPUs - whether from local or remote sources - the MemoryAlloy technology achieves full parallelism throughput, scaling aggregate bandwidth to over 250 GB/s.
This optimization is particularly beneficial for models utilizing lower Tensor Parallelism configurations (e.g., TP1, TP2, or TP4). Although these models do not compute on all available GPUs, MemoryAlloy technology allows them to utilize parallel transfer capabilities, as if they were running on more GPUs. Consequently, these configurations enjoy the acceleration of parallelized transfers when pulling latency-sensitive data, such as KV cache, into target GPUs.
On additional applications such as disaggregated serving, a lot of GPU to GPU local transfers are required. For these we also achieve theoretical throughput, for example on NVIDIA H100 using NVlink that would be around ~450GB.
Core mechanisms: Send graph and shadow pools
The high-throughput capabilities of MemoryAlloy technology rely on two symbiotic features: Shadow Pools and the Send Graph.
- Shadow Pools are pre-allocated, mapped memory regions on the GPU that act as efficient staging grounds for data. They serve multiple purposes, for the Send Graph feature and also eliminating the overhead of repeated memory registration to NICs and allocation costs.
- The Send Graph serves as the orchestration engine that manages these pools. Instead of performing simple point-to-point copies, it constructs a directed acyclic graph (DAG) to slice transfers into pipelined chunks. It routes these chunks through intermediate Shadow Pools on neighboring devices and reassembles them at the destination.
Crusoe's MemoryAlloy technology is written in Rust 🦀, has Python bindings, and includes our custom CUDA/ROCm kernels for different data movement and RDMA flows.
Cluster-wide caching and efficiency
Unlike per-model or per-instance CPU offload layers, the MemoryAlloy technology acts as a true cluster-wide shared cache. Any model instance can retrieve KV segments generated anywhere in the cluster, allowing effective KV-cache capacity to scale linearly with the number of nodes rather than being limited to what exists locally. For example, an eight-node NVIDIA H100 cluster provides more than 6-1.4 TB of unified KV storage instead of 640-1.4 GB isolated per node (assuming 60%-70% usage of DRAM for caching).
To keep this distributed cache efficient, we include a global eviction manager that tracks usage patterns across nodes. It automatically reclaims memory from inactive or stale KV segments and applies adaptive policies such as LRU and LFU, ensuring that the most relevant context stays resident while keeping utilization balanced across the cluster.
These performance characteristics and behaviors have been validated across multiple accelerator families, including NVIDIA HGX™ H100, H200, and B200, and AMD MI300 systems.
Crusoe’s gateway
Our gateway is the single intelligent entry point to the entire inference cluster. It operates as a real-time scheduler rather than a simple proxy. Its core responsibility is to serve as an effective load balancer that maximizes throughput and minimizes latency by making smart, model-aware routing decisions. Achieving this requires a precise understanding of the computational cost of each request, so the gateway continuously tracks the KV-cache state of every engine, including which KV blocks already reside on each GPU.
Building on this information, the gateway avoids routing decisions that overlook the quadratic cost of attention on long prompts by explicitly estimating the prefill cost (TTFT) for every incoming request. When combined with the KV blocks already available on each engine, the gateway can accurately predict the effective cost of serving the request on each candidate engine.
This KV-aware TTFT routing allows the scheduler to select the engine that can deliver the earliest time to first token. Engines that hold more of the required KV segments effectively bypass large portions of quadratic attention compute, which dramatically reduces TTFT for long or recurring prompts. As a result, the gateway prevents large queries from blocking smaller ones, leverages compute already invested in previous requests, and maintains consistently high GPU utilization across the cluster.
To maintain predictable performance under load, the gateway includes a configurable back-pressure mechanism. Each model can define its own strategy such as queue depth thresholds, TTFT-based admission control, or SLO-driven throttling to ensure latency remains stable even at high concurrency. This gives operators fine grained control over capacity, fairness, and latency guarantees.
Together with distributed KV-cache sharing, KV-aware TTFT routing and model-level back-pressure create an efficient scheduling layer that keeps latency low and throughput high across the cluster.
Experiments and benchmarks
Our benchmark suite is designed to guide system development by enabling targeted hill-climbing, accelerating iteration cycles, and removing noise from performance evaluation. By combining synthetic and real-world scenarios, our benchmarks strike a balance between control and realism. This allows us to isolate specific system bottlenecks while also validating performance under production-like conditions.
Synthetic benchmarks provide clean, deterministic testbeds that enable precise stress testing and metric optimization, such as reducing TTFT under controlled cache behavior. This helps us iterate rapidly, detect regressions early, and focus on high-impact architectural improvements.
Real-world benchmarks simulate diverse user behaviors and workloads by leveraging a broad mix of natural prompts and datasets. These tests expose how our systems perform under realistic distributions, helping us identify edge cases and ensure robustness in the face of complex, noisy inputs.
Together, these benchmarks form the backbone of Crusoe’s performance evaluation pipeline. They enable data-driven decisions, faster tuning cycles, and scalable quality assurance across a wide range of deployment scenarios. All experiments in the following sections were conducted on a cluster of NVIDIA H100 GPUs, served on Crusoe’s high-performance infrastructure.
Measuring cache hit performance
The goal of this experiment is to quantify the performance gain achieved when reusing cached prompts from Crusoe's MemoryAlloy technology instead of recomputing them from scratch. In practice, this measures how quickly an engine can serve a request when the corresponding KV cache already exists, either locally on the same node or remotely elsewhere in the cluster.
Figures 1 and 2 illustrate these results for the Llama-3.3-70B model across multiple prompt lengths. When vLLM experiences a cache miss (that is, the prompt has been evicted and must be fully recomputed), TTFT grows steeply with input size. In contrast, pulling the same cached prompt from Crusoe's MemoryAlloy technology reduces latency by more than an order of magnitude, whether the cache resides locally or on a remote node. For 110K-token prompts, local reuse delivers up to 38x faster TTFT, while remote reuse remains extremely close at 34× faster. Even at shorter lengths, around 30K tokens, we observe 21x speed-ups compared to cold prefill.
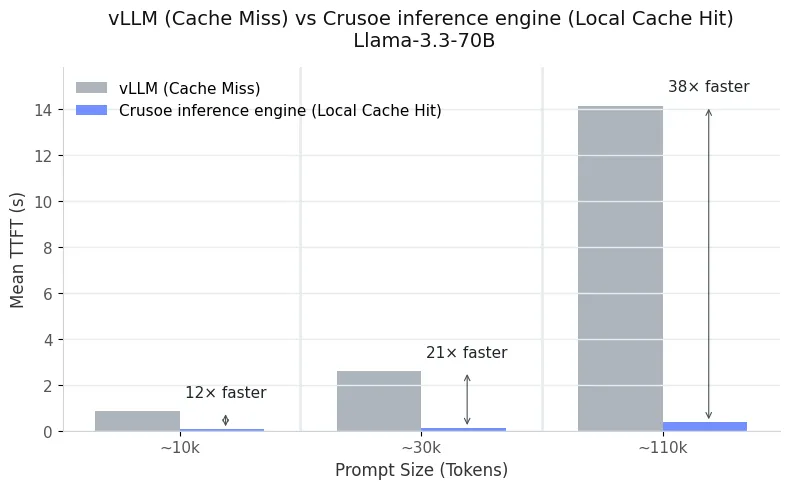
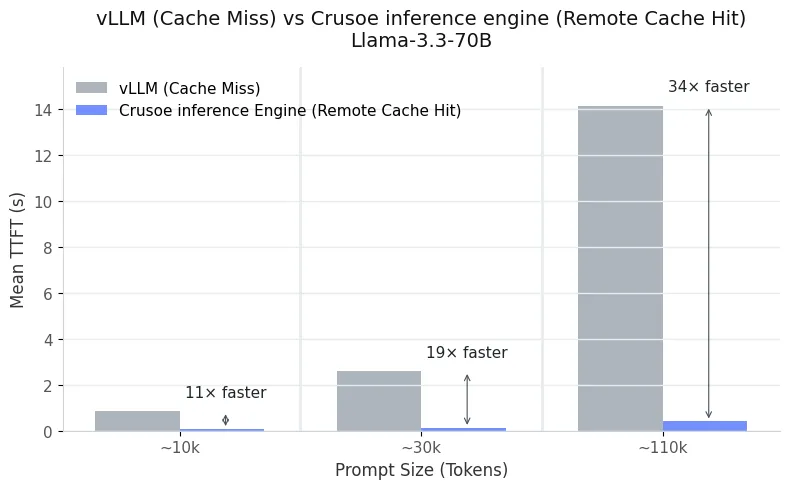
This consistency highlights the strength of our distributed memory fabric. Remote cache access behaves nearly identically to local access. A vLLM engine on node A can instantly leverage KV segments computed on node B and vice versa without serialization overhead or redundant computation.
Consider Llama-3.3-70B running on 4× NVIDIA H100 GPUs. Each instance provides roughly 140 GB of available GPU KV cache capacity. On the same node, Crusoe’s MemoryAlloy technology extends this to nearly 1 TB of accessible GPU-resident KV cache through aggregation and RDMA-based sharing, giving each engine access to about 7x more KV storage than it could manage alone.
As the cluster scales, this advantage compounds. Each additional node contributes its GPU KV capacity to the shared memory pool, linearly expanding the global cache surface area. The probability of cache hits increases proportionally with cluster size, allowing larger clusters to achieve lower average latency, higher throughput, and better resource utilization. In this way, Crusoe’s inference engine turns scaling out into both a capacity and a performance multiplier.
Finally, we compare our distributed cache performance to the system’s practical roofline, a direct on-GPU cache hit. Figure 3 shows that both intra-node and inter-node cache hits operate remarkably close to this upper bound. Even for 110K-token prompts, pulling KV segments from Crusoe's MemoryAlloy technology takes only slightly longer than reading them directly from GPU memory.
This demonstrates that Crusoe's MemoryAlloy technology delivers near-on-GPU performance across the cluster, making remote cache reuse virtually indistinguishable from local access.
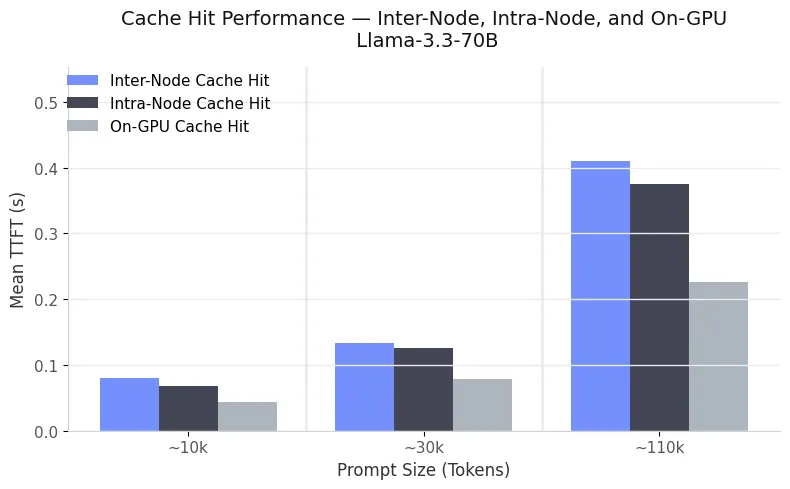
Application: Long document question answering
While Crusoe’s inference engine with MemoryAlloy technology benefits many workloads, its impact is most pronounced when prompt prefixes repeat or large contexts are accessed multiple times. Long-document question answering, multi-turn chat, code completion, and agentic workflows all share this pattern: the system repeatedly encounters overlapping contexts, allowing a growing set of precomputed KV segments to be reused and significantly reducing TTFT.
To evaluate this in a realistic setting, we tested Llama-3.3-70B and GPT-OSS-120B on a long-document QA workload using the [1] DocFinQA dataset. DocFinQA consists of long financial documents paired with questions that require repeatedly scanning the full context. We built a prototype application that simulates users querying documents from this corpus, making it well-suited for measuring the effects of KV reuse under real access patterns.
Each model instance was deployed as it would be in production. The Crusoe gateway applied KV-aware TTFT-based routing for load balancing and scheduling, and the MemoryAlloy technology provided the distributed KV-cache layer. For comparison, we ran vLLM under the same gateway and routing strategy so that performance differences isolate the contribution of Crusoe’s inference engine and the MemoryAlloy technology's cluster-wide caching.
In this workload, a single vLLM engine typically handled about 10 parallel requests for Llama-3.3-70B and around 20 parallel requests for GPT-OSS-120B. Both models saw the same document-length distribution: most inputs clustered around 25k tokens, with occasional ≈100k-token documents. As we scaled the number of nodes and the number of vLLM instances, we also doubled the number of users and documents diversity, while maintaining this same distribution.
Results
Single-node deployment
We began by evaluating Crusoe’s inference engine in a single-node setup to measure the direct impact of MemoryAlloy technology on latency and throughput. Across all prompt lengths, the improvements were clear.
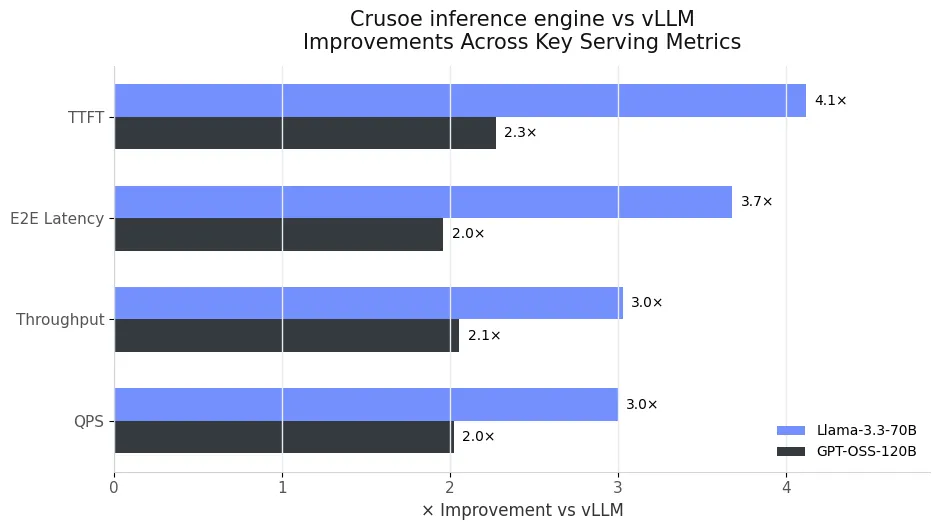
- For Llama-3.3-70B, median TTFT dropped from 0.7s on vLLM to 0.17s with Crusoe’s MemoryAlloy technology, a 4x reduction overall and up to 20x faster for long prompts (64K to 128K).
- Median end-to-end latency fell from 9.0s to 2.45s, resulting in 3.7x faster responses on average.
- We saw strong gains for GPT-OSS-120B as well: TTFT improved from 0.5s to 0.22s, and end-to-end latency dropped from 4s to 1.99s. The smaller gap compared to Llama is explained by GPT-OSS-120B having faster prefill times, but the relative improvement from MemoryAlloy technology is still significant.
This efficiency translated directly into more serving headroom.
- For Llama-3.3-70B, throughput rose from 7k to 21k tokens per second, a 3x increase, with QPS showing a similar improvement.
- For GPT-OSS-120B, throughput increased from 53k to 110k tokens per second, again with a comparable improvement in QPS.
Figure 4 summarizes these results, showing how MemoryAlloy technology turns single-node caching into a major performance advantage. The gap between vLLM and Crusoe’s inference engine grows with input length across both models, demonstrating how shared memory removes the quadratic prefill bottleneck that dominates long-context workloads.
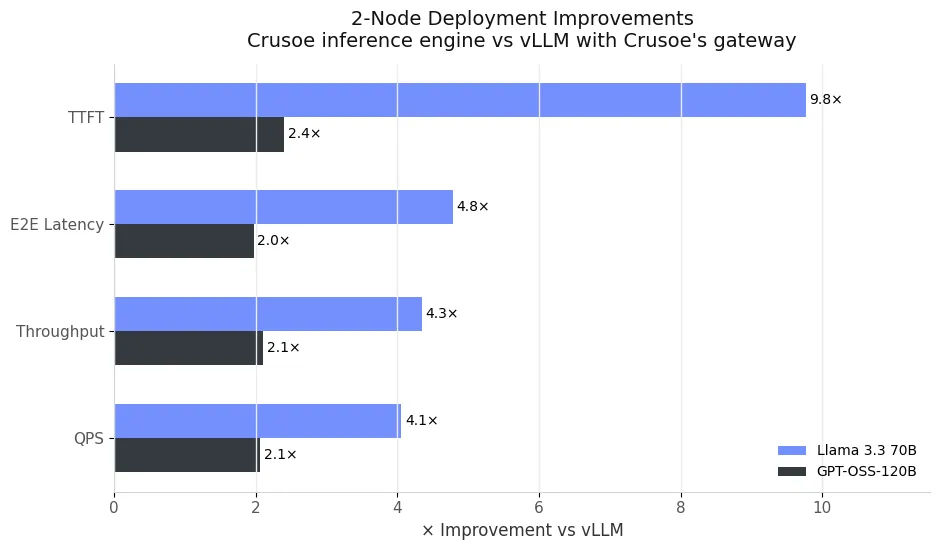
Two-node deployment
We then extended the test to a two-node configuration, using the same Crusoe gateway for both systems. The workload was scaled to include twice the number of users and twice the number of documents, simulating a heavier multi-user environment.
Even under higher load, Crusoe’s inference engine maintained its latency advantage and scaled close to linearly with additional nodes. Throughput increased from 21k to 53k tokens per second for Llama-3.3-70B and from 95k to 200k tokens per second for GPT-OSS-120B. Compared to vLLM with our gateway, this represents a 4.3x improvement for Llama and a 2.1x improvement for GPT-OSS, confirming that our distributed KV cache layer and cache reuse scale efficiently across nodes without introducing latency overhead.
Scaling beyond two nodes
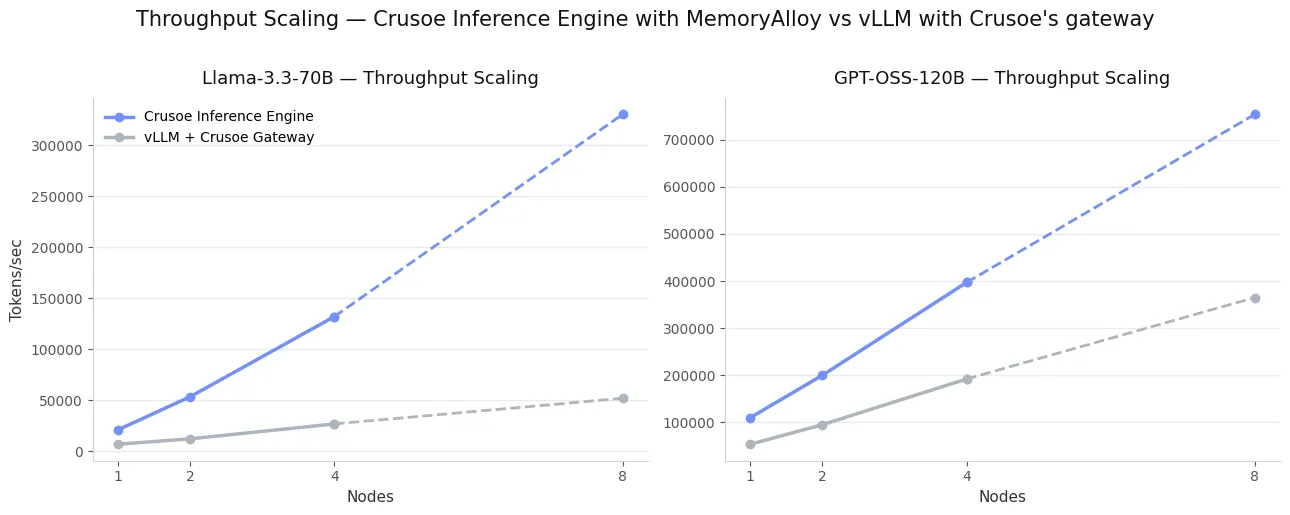
Finally, we extended the experiment to 4-node and 8-node deployments, doubling both the number of users and the number of documents at each step while keeping the same gateway configuration. Crusoe’s inference engine continued to scale close to linearly.
For Llama-3.3-70B, throughput more than doubled when moving from 2 to 4 nodes, reaching 132k tokens per second, nearly a 5x advantage over vLLM’s 26.9k at the same scale, and extrapolated to 330k tokens per second at 8 nodes. GPT-OSS-120B followed the same pattern, climbing to nearly 400k tokens per second at 4 nodes with an extrapolation of 760k at 8 nodes. Under the same routing and load, vLLM’s throughput grew far more slowly across both models.
Figure 6 summarizes these results, showing how MemoryAlloy technology enables near-linear throughput growth as the cluster expands, while vLLM stalls due to its local-only caching and absence of cross-node reuse.
Application: Chat sessions
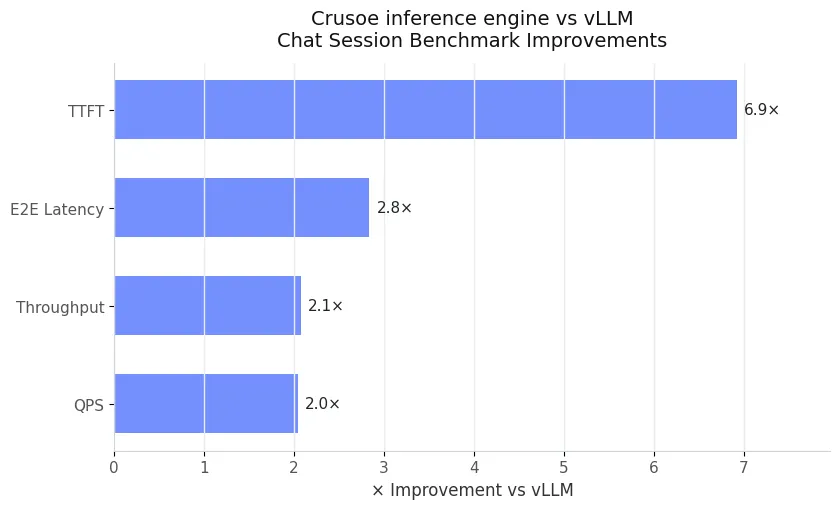
To further validate our results, we evaluated performance on vLLM’s [2] Multi-Turn Chat Session benchmark, which simulates interactive conversations composed of a global system prompt and per-user session prompts. We used the same production-style deployment as in the long-document QA application, comparing Crusoe’s inference engine with MemoryAlloy technology against vLLM under identical KV-aware TTFT-based routing, using Llama-3.3-70B.
In this setup, a single vLLM engine typically handled around 10 parallel user sessions, with conversations averaging about 10k tokens in total and roughly 10 turns per chat. This distribution remained consistent throughout the experiment. As we scaled to more nodes and more engine instances, we proportionally increased the number of concurrent users while maintaining the same conversation-length and turn-count characteristics.
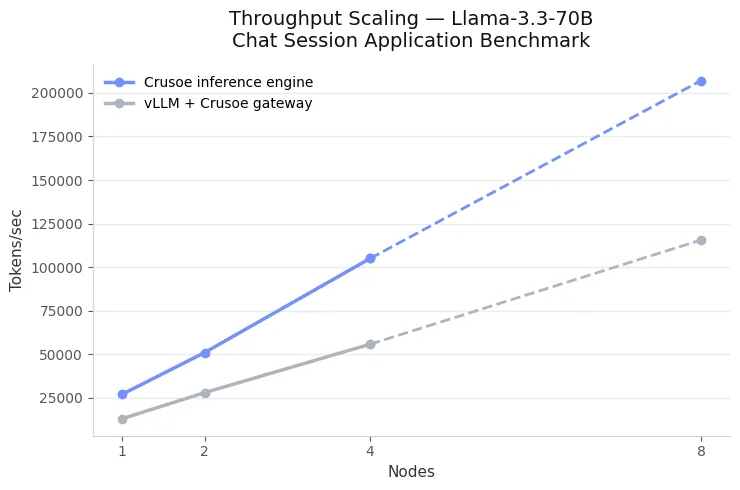
The results mirrored the patterns observed in long-document QA. On a single node, Crusoe’s inference engine reduced TTFT by 7× and nearly doubled serving capacity. At two nodes, throughput increased from 27k to 51k tokens per second while keeping TTFT flat. Extending to four nodes preserved this near-linear trend: Crusoe consistently delivered sub-150 ms TTFT and reached about 105k tokens per second, while vLLM scaled more slowly under the same routing and load.
Figure 8 shows throughput scaling across 1, 2, and 4 nodes, including an extrapolation to 8 nodes, confirming that the benefits of distributed KV-cache reuse carry over directly to interactive chat workloads.
What’s next for Crusoe’s inference engine
At Crusoe, we are determined to build the most advanced and reliable managed inference platform for AI models. build the most advanced and reliable managed inference platform for large language models. We are driven by a clear goal: to make every stage of AI inference faster, smarter, and more efficient.
In this post, we highlighted our distributed KV cache, Crusoe's MemoryAlloy technology, which dramatically reduces prefill times and unlocks much higher GPU utilization by removing the bottlenecks caused by large, repetitive prompts.
This is just the beginning. In our upcoming posts, we will explore how we are accelerating the next phase of inference, decoding, through techniques such as speculative decoding, quantization, model pruning, and more. Together, these efforts represent our continued commitment to redefining what is possible in large-scale, energy-efficient AI inference. Sign up to get started with Crusoe Managed Inference.
References
[1] [2401.06915] DocFinQA: A Long-Context Financial Reasoning Dataset
[2] https://github.com/vllm-project/vllm/tree/main/benchmarks/multi_turn


