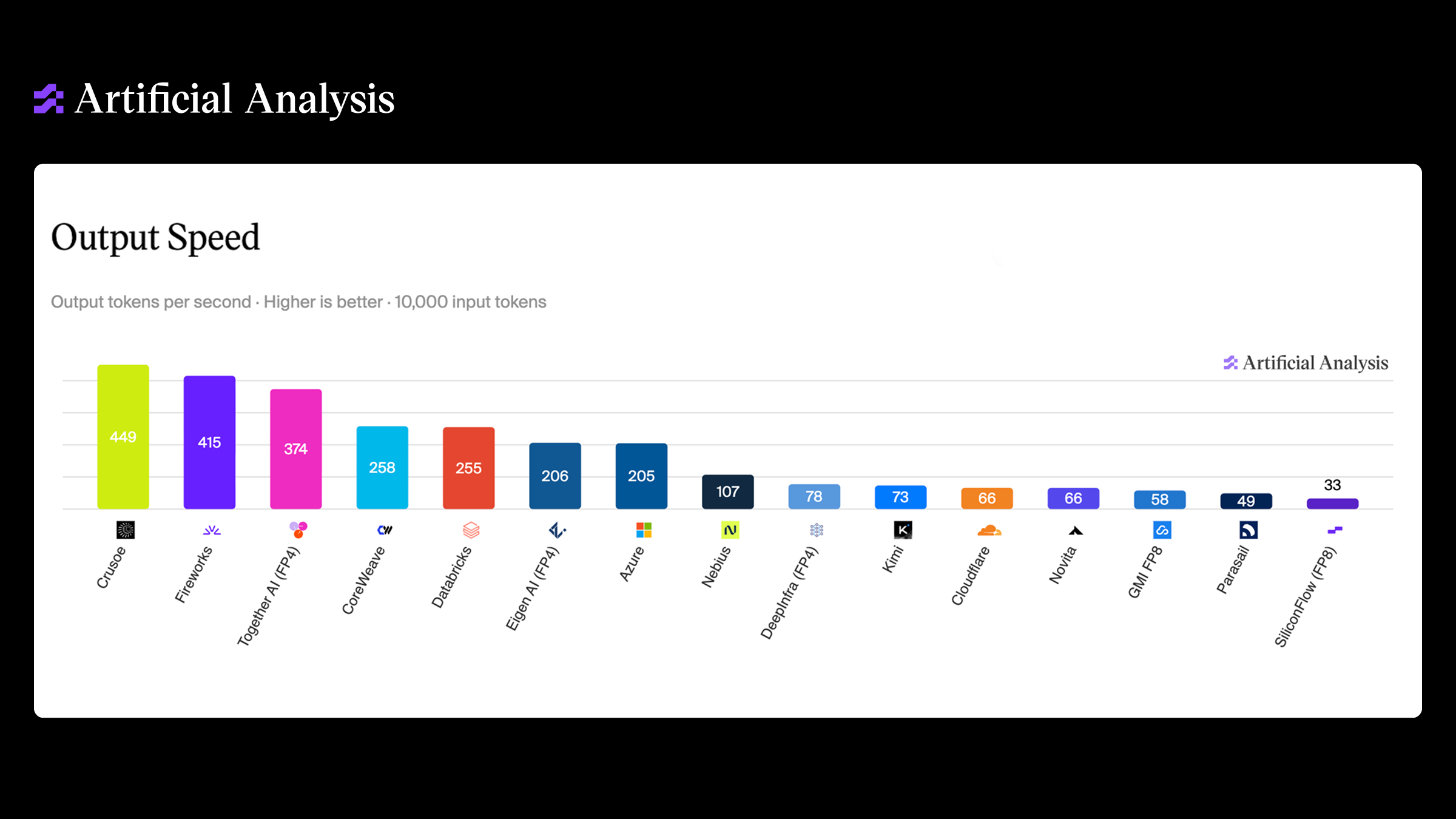
Crusoe Managed Inference: Optimize performance for the most demanding AI workloads
Crusoe Managed Inference uses cluster-native KV caching (Crusoe's MemoryAlloy technology) to achieve 9.9× faster TTFT and 5× higher throughput for demanding AI workloads.



Every app developer building with AI products eventually faces the "iron triangle" of inference: speed, throughput, and cost. The fundamental tension between these three critical elements forces a difficult choice: sacrifice user experience (UX) for budget, or vice versa. This tension is only increasing as models rapidly grow in size, complexity, and required context to deliver the "right" answer.
We believe the future of AI inference isn't about choosing one corner of the triangle; it's about pioneering new techniques that break the trade-off entirely.
Today, we're launching Crusoe Managed Inference, powered by our proprietary inference engine with Crusoe's MemoryAlloy technology. This purpose-built solution is optimized for the most demanding AI workloads like large context and long-form text generation. AI developers can use the new Crusoe Intelligence Foundry to rapidly deploy and automatically scale production-ready models, instantly enabling new capabilities like AI agents and complex task automation.
By eliminating the root causes of resource waste (which we will detail below), we win back precious milliseconds in Time-to-First-Token (TTFT), deliver breakthrough throughput, and drastically increase efficiency. This ensures your service remains lightning-fast and responsive, even under peak demand, allowing you to deliver a premium UX without straining your budget.
Today, Crusoe Intelligence Foundry offers developers access to run the world's top open-source models including Kimi-K2 Thinking, Llama 3.3 70B Instruct, Gemma 3 12B, gpt-oss-120b, Qwen3 235B A22B Instruct 2507, DeepSeek V3 0324, and DeepSeek R1 0528.
Read on to see how we solve two major scaling bottlenecks and provide a powerful, simplified path to production.
The problem: Re-processing and resource waste
Typical inference deployments have scenarios where context is shared across repeated user queries. Think of coding generation interacting with a shared codebase or long document question answering referencing shared context.
These workloads encounter two major bottlenecks that undermine performance:
- Duplicate prefills: Multiple users or sessions often send prompts with identical prefixes or contexts (e.g., system prompts, multi-turn history). Traditional engines perform the expensive "prefill" computation for that prefix every single time, wasting GPU cycles and increasing TTFT.
- Limited KV cache sizes: Even when engines are optimized to retrieve duplicate prefills from a cache, KV cache sizes are typically locally managed per GPU or node, limiting how much context can be re-used, affecting throughput and TTFT under load.
The solution: Cluster-native KV cache and fabric
Crusoe's MemoryAlloy technology, which fuels our inference engine, is fundamentally different because it is designed to optimize resources and knowledge sharing across the entire cluster, not just a single GPU.
1. Breakthrough speed
We have achieved 9.9x faster TTFT compared to optimized community solutions like vLLM (using the Llama 3.3 70B model). How? By eliminating the redundant prefill problem with a unique cluster-wide KV cache fabric. Read our technical blog for a deep dive into the tech stack and our benchmarking methodology.
Instead of re-calculating common prefixes, our inference engine instantly fetches the pre-computed prefix cache from a local or remote node via our low-latency, purpose-built AI network. For users, this means real-time responsiveness as the first token arrives almost instantaneously. For your budget, it means eliminating wasted compute per token.
2. Superior throughput with dynamic optimization
Simply achieving low latency for one user isn't enough; true production readiness requires high throughput at low latency for thousands of concurrent users. Crusoe’s inference engine can process up to 5x more tokens per second* for workloads with frequent prefix re-use. This approach can dramatically reduce input-token spend by only processing each token once, allowing your application to handle sudden load spikes while preserving a flawless user experience.
We also offer speculative decoding, reducing the compute cost per token, and dynamic batching, optimizing batch size in real-time to keep GPUs fully utilized without sacrificing the tail latency of any single user.
3. Seamless elastic scaling
Meet changing workload demands with scaling that is managed for you, and reliable even when loading large models like Qwen3.
Multiple use cases benefit from these optimizations
Experience next-level AI inference today
The tradeoff between a premium user experience and cost control is less of a false choice. Crusoe Managed Inference, powered by our unique MemoryAlloy technology and delivered through the Crusoe Intelligence Foundry, redefines the paradigm and removes the operational burden entirely.
Ready to accelerate your app development with speed, control, and integrity? Explore the platform and start building with the latest AI-native performance. For an in-depth look at our distributed KV cache solution and benchmarking methodology, read our technical post on the MemoryAlloy technology architecture.