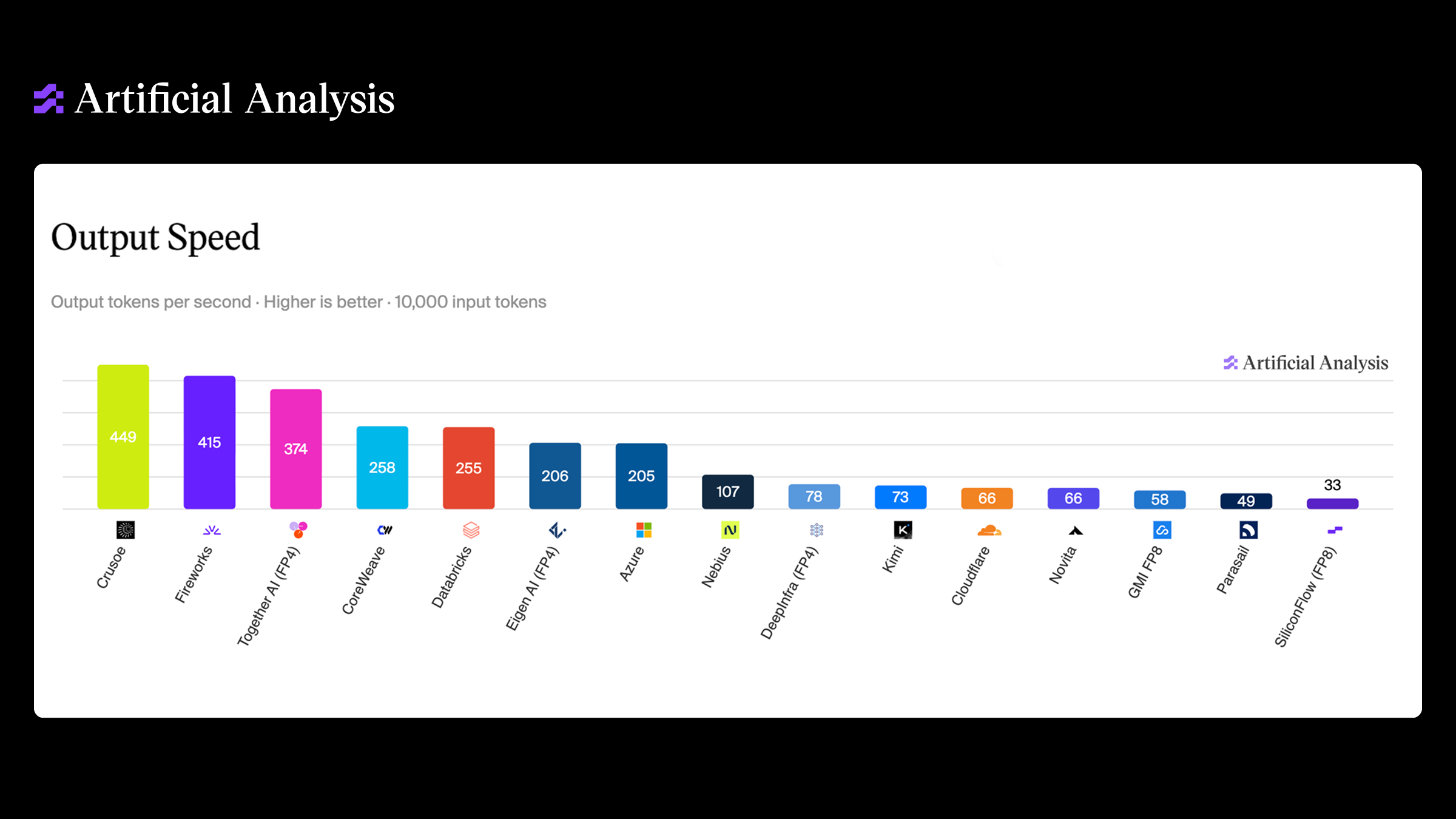
Building the world’s favorite AI cloud
Crusoe's SVP Product shares 2025 momentum, the launch of Bring Your Own Model for Managed Inference, and why we're building the world's favorite AI cloud.

.avif)
When I joined Crusoe last August to lead our Cloud product team, I did so with a single, clear goal: to build the world’s favorite AI cloud. I’ve built infrastructure products and services throughout my career and know first-hand how infrastructure can either accelerate or stifle innovation. AI has transcended being just another workload running on a multi-purpose cloud. It is now the workload with the most demanding and the fastest changing requirements ever. We have entered a different era of computing.
I came to Crusoe because I saw an opportunity to empower AI engineers to build the future of intelligence in this new era. Crusoe is building a platform that gets out of your way so you can focus on what matters: innovating by building and optimizing AI models that power AI agents needed to operate at scale.
Now that 2026 is well underway, I want to share an exciting update to our platform today, the progress we’ve made, and why I am more excited today than I was on day one.
Today’s news: Bring your own model for Managed Inference
Innovation at Crusoe isn't a roadmap item; it's a constant drumbeat. Today, we are excited to announce that customers can now use Crusoe Managed Inference with their own models, whether they trained them from scratch or optimized an open model. Our Managed Inference is the fastest way to deploy the world’s leading open-weights models like DeepSeek, Qwen, Kimi or gpt-oss. Now, we are opening that same "best-in-class" speed, throughput, and reliability to your proprietary IP.
Customers who build their own models or invest significantly in optimizing their favorite open model are now routinely benchmarking their current inference price/performance baseline with Crusoe. We have observed multiple instances of gains more than 4x in Queries Per Second (QPS) with lower latency, leading to superior performance at a lower price - a win/win for all!
When you bring your own model to our platform, our team will work directly with you to optimize performance based on your unique weights and architecture, enabling you to scale quickly and reliably, with SLA guarantees on the managed API endpoint we operate for you. This is a unique value proposition that hyperscalers do not offer: Work with the AI specialists at Crusoe and let’s scale together.
Momentum at scale
We are committed to making Crusoe Cloud the premier destination for AI models and agent development. By focusing on product innovation, capacity expansion, and customer success, we achieved significant growth across every core pillar of our cloud business in 2025:
- Approximately 17x YoY growth in added total contract value. This represents deep, multi-year commitments from the teams building the future.
- 150% YoY growth in cloud ARR, driven by strong adoption from AI Native companies who need a platform that understands distributed training and high-scale inference.
- Approximately 70% Increase in New Logos: From robotics to coding assistants, the diversity of our customer base is a testament to the versatility of our stack.
- Raised $1.375 Billion Series E at a $10B+ Valuation: Led by Valor Equity Partners and Mubadala Capital, our Series E gives us the fuel to keep building as fast as our customers are dreaming.
Empowering the builders
The true measure of an AI cloud isn't the number of chips in the rack; it’s the success of the people using them. In 2025, Crusoe Cloud became the foundation for teams who are literally redefining reality:
- Cursor: Transforming how every developer on earth writes code.
- 1X: Proving that humanoid robotics can scale when they have the right low-latency foundation.
- Odyssey: Delivering the next generation of creative expression through video and 3D world-building.
- Fireworks: Leveraging our high-performance clusters to push the boundaries of model inference efficiency.
- Yutori: Building agents that can autonomously navigate websites and execute tasks on the web
Innovating up the stack
In 2025, we innovated beyond the infrastructure layer to deliver a software-defined solution that helps customers balance speed, throughput and cost.
Crusoe Managed Inference
In November 2025 we launched Crusoe Managed Inference, a fully managed service that allows developers to deploy leading open/open-source models like Qwen3 and DeepSeek with a single API call. Through the new Crusoe Intelligence Foundry, AI developers can discover models, generate API keys in minutes, and transition from model checkpoint to global production without managing the underlying GPU clusters.
MemoryAlloy™ Technology
Crusoe’s inference engine is powered by our proprietary MemoryAlloy technology, a cluster-native KV cache fabric. Unlike traditional engines that re-process context for every query, MemoryAlloy technology allows GPUs to share and fetch prefix caches across the entire cluster instantly. By bridging the gap between hardware and software, we’ve achieved 9.9x faster Time-to-First-Token (TTFT) and 5x higher throughput for demanding workloads compared to standard commodity cloud configurations like vLLM. As context windows for modern AI workloads grow, so does the memory required for the prefill phase of inference. MemoryAlloy technology decouples the KV cache from individual model processes and exposes it as a shared resource. GPUs can share and fetch prefix caches across an entire cluster instantly.
AutoClusters on Crusoe Managed Kubernetes
We’ve delivered Crusoe AutoClusters on top of our Crusoe Managed Kubernetes (CMK) service, a system designed to improve GPU cluster reliability and effective performance. At the scale of frontier AI training, hardware glitches are no longer exceptions – they are background noise, often occurring every few hours. With AutoClusters, we’ve automated the detection and remediation of common GPU failure modes, providing end to end transparency and observability throughout the process. This increases your "goodput" - the rate of actual useful work - and helps accelerate training runs. With AutoClusters, infrastructure reliability is no longer something you have to worry about. As of January 2026, CMK is used in production by a significant portion of our customer base already.
Talent density
Finally, our momentum is a direct result of the talent we’ve attracted and retained across our global hubs. There has been much discussion in the industry about the "war for talent" and the movement of engineers between the giants and the upstarts. My perspective is simple: it’s not about the headcount. It’s about the talent density.
Crusoe is proud to have retained and recruited a team of 10x engineers – the architects and developers who aren’t interested in maintaining legacy systems or chasing the newest trend, but in inventing the foundational stack for the next century.
Our acquisition of Atero in August allowed us to establish a world-class Tel Aviv office, whose deep experience in hardware-software co-design has integrated seamlessly with our powerhouse teams in San Francisco and Sunnyvale. The technical caliber of our global engineering team allowed us to deliver our Managed Inference service powered by MemoryAlloy technology in record time, setting a new bar in breakthrough latency and throughput for AI inference.
Our engineers around the globe share a singular DNA: they are builders who want to create the AI cloud they would actually want to use. We are continuing to hire these types of world-class innovators across all our locations.
Everything we achieved in 2025 was just the beginning. To meet the accelerated demands of the AI ecosystem, we are rapidly expanding and optimizing every system within our growing, purpose-built AI cloud. We turn our know-how into IaaS and Managed AI products, which help fuel our customers' ambition. If you’re a builder who wants to solve the hardest AI problems from energy to intelligence, join us.