Introducing Command Center: The unified operations platform for AI workloads
Crusoe Command Center automates orchestration, observability, and support across your AI stack — replacing fragmented monitoring with a single source of truth to deliver more uptime, less triage.

You’ve assembled the talent, secured the budget, and designed the architecture to bring your AI vision to life. But whether you’re midway through a multi-week foundation model training run or scaling a high-throughput inference service to production, the underlying infrastructure often starts feeling like a black box.
Velocity often stalls not because of your code, but because of the "unknown unknowns" — silent GPU underutilization, untraceable networking drops, or workloads that fail in the middle of the night without a clear root cause. As models evolve and demands on compute increase, teams face compounding complexities trying to maintain peak performance while engineers are forced to context-switch between fragmented monitoring dashboards.
The fact is, if you can't see a bottleneck, you can't fix it. This isn’t a people problem; it’s an observability problem. That’s why today, we’re introducing Crusoe Command Center, a unified operations platform designed to increase the resilience of your entire AI stack by automating orchestration, observability, and support – to deliver more uptime, less triage.
Command Center delivers the high-fidelity data foundation required to monitor, diagnose, and optimize massive AI workloads. At its core, Command Center replaces fragmented monitoring with a single source of truth, ensuring every GPU in your cluster is visible and accountable.
Why we built Command Center
Modern AI workloads demand infrastructure that can keep pace with your ambition – systems that orchestrate thousands of GPUs without manual intervention, observability that surfaces issues before they cascade, and support that feels like an extension of your team rather than a ticket queue.
We built Command Center to enable autonomous infrastructure that reduces operational friction, maximizes the reliability of your AI stack, turns blind spots into actionable insights, and offers collaborative expert support.
Reduce operational friction
Reducing friction starts with intelligent orchestration. Command Center seamlessly integrates with Crusoe Managed Kubernetes (CMK) so you can spin up clusters quickly and have access to a comprehensive view of your system on day one.
For massive training runs, CMK also supports Crusoe Managed Slurm, allowing you to leverage Slurm’s orchestration within a Kubernetes-native framework. This means your multi-week training jobs can run continuously across hundreds of GPUs—exactly what frontier AI demands.
When you’re up and running, Crusoe continuously monitors your system and exposes real-time data in Command Center for full transparency into the health and utilization of your resources.
Maximize the reliability of your AI stack
Resilient fleets result in more consistent training and scalable inference. And while Kubernetes is the industry standard for managing cloud-native infrastructure for good reason, GPU clusters fail in ways that traditional cloud infrastructure does not. Simple alerting often comes too late or leads to alert fatigue, causing teams to spend more time managing their infrastructure instead of their models.
We launched AutoClusters to help you run training or long-running GPU workloads in high-utilization environments, without the need for manual operations at scale. AutoClusters remediates hardware failures automatically within your CMK workloads. By detecting performance degradation and evicting compromised nodes in favor of healthy instances from a reserve pool, AutoClusters ensures your Kubernetes-based training or inference stays resilient without 24/7 babysitting.
AutoClusters turns GPU health into a first-class control loop by continuously monitoring, detecting, and remediating. Command Center gives you visibility into the control loop so you can see your GPUs maximizing compute time, not waiting to be fixed.
Turn blind spots into actionable insights
Managing AI infrastructure shouldn’t feel like a guessing game. As models and clusters grow in complexity, performance bottlenecks often become obscured. Command Center is designed to bring more transparency to these environments, providing deep observability into the granular data points that matter most for both high-scale training and production inference.
Out-of-the-box telemetry delivers the real-time visibility required to identify performance bottlenecks and maximize resource efficiency across your infrastructure. By tracking individual GPU health, storage, and network metrics alongside usage and spend, you can build without the resource blind spots that lead to inefficiency.
These insights are available exactly where you need them: use Command Center for UI-based troubleshooting, Grafana via PromQL API for programmatic access, or the Prometheus endpoint for continuous monitoring via scraping. Telemetry Conduit (now in limited availability) streams pre-defined infrastructure metrics directly to your preferred tools, effectively eliminating data silos and tab-switching. This ensures your infrastructure data lives alongside your broader operational environment without requiring you to change your workflow.
Beyond standard infrastructure tracking, we have extended visibility to support custom metrics. By pairing the Crusoe Watch Agent with Telemetry Conduit, you can ingest application-level data from CMK for end-to-end visibility across your entire AI infrastructure stack. This allows you to correlate specific workload performance with underlying GPU vitals, helping you identify exactly how software bottlenecks or code changes are impacting hardware utilization.
When issues do occur, out-of-the-box logging for CMK provides easy access to journald and Kubernetes logs; no more hunting through SSH sessions or waiting for log dumps. You restore service faster and keep your workloads moving.
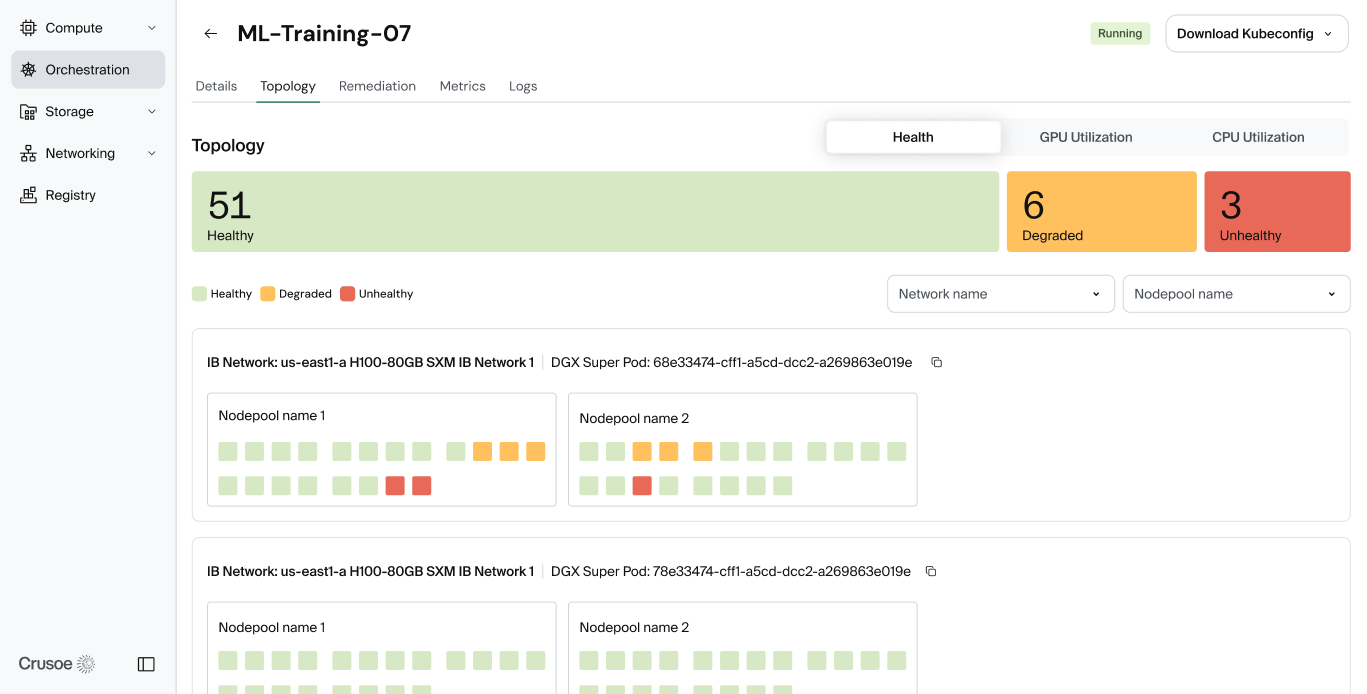
Finally, a new Topology view provides a comprehensive look at GPU health arranged in topological format, so you can pinpoint nodes with issues in a topology-aware context to understand their impact on training workloads.

Collaborative expert support
Traditional cloud support operates on ticket-driven SLAs. Command Center operates on partnership.
Through our new Notification Center, critical alerts are streamed directly into your Slack or webhooks, while our engineers partner with you to architect clusters purpose-built for your specific model architecture.
Move from maintenance to momentum today
Crusoe Command Center removes the operational burden of AI infrastructure. With automated orchestration, observability and support, your team can exit maintenance mode and focus on what matters: the next breakthrough.
Ready to build on infrastructure that manages itself? Learn more about Command Center or contact our team to discuss how we can support your specific workloads.