430+ tokens per second: optimizing Kimi K2.6 and K2.7 for production
How Crusoe built the fastest Kimi K2.6 and K2.7 deployments on Artificial Analysis, reaching 430+ output tokens/sec through custom kernel optimization, speculative decoding, and disaggregated serving.




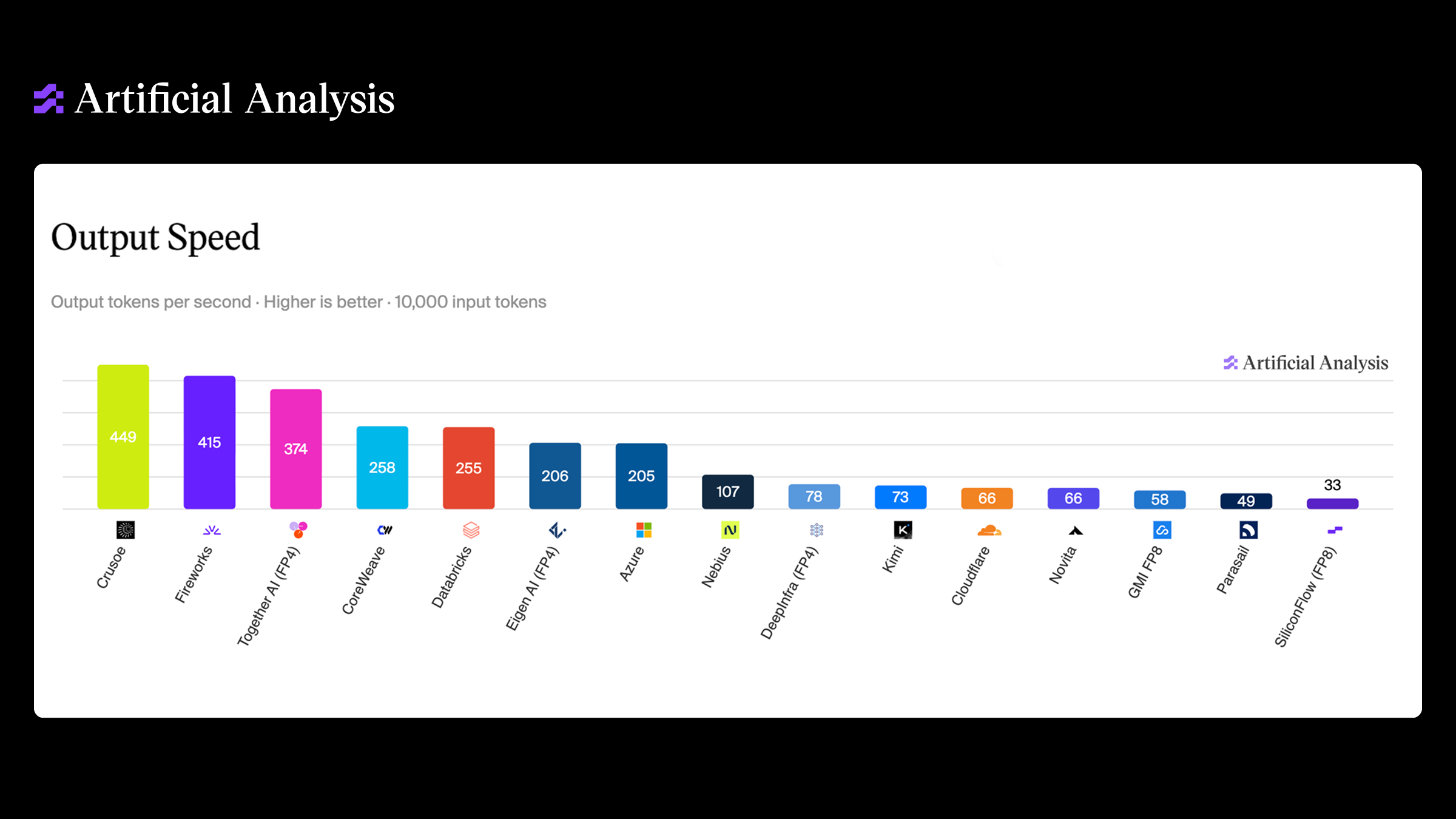
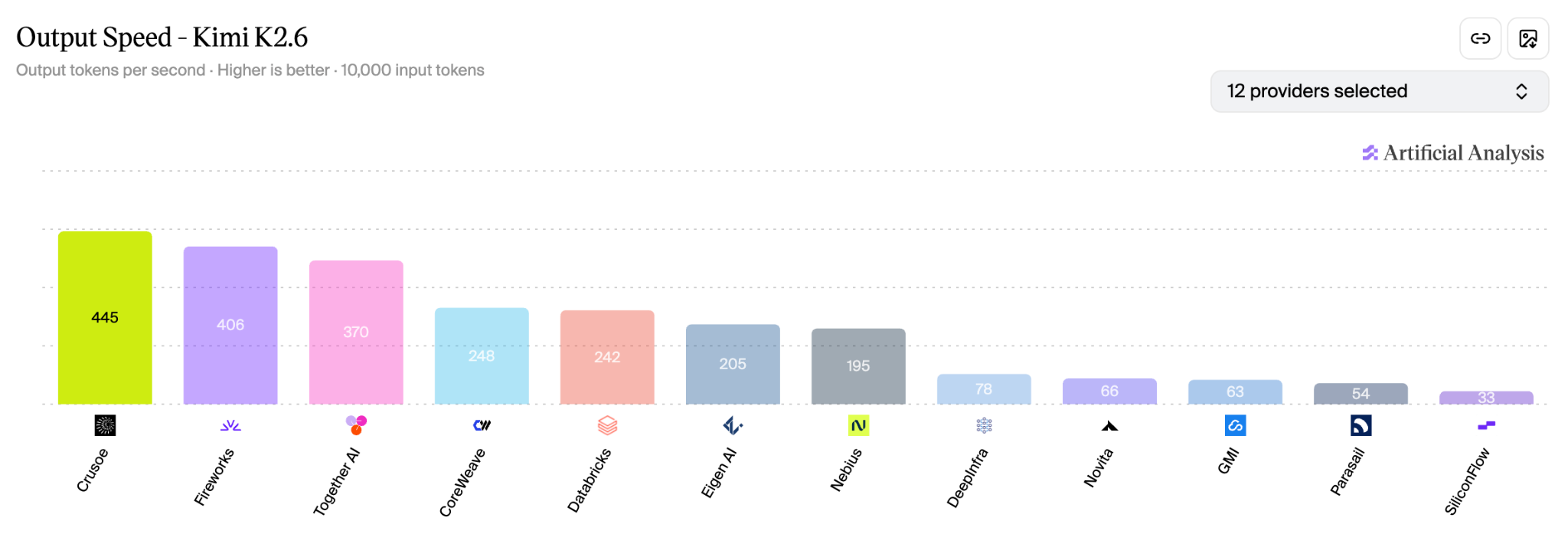
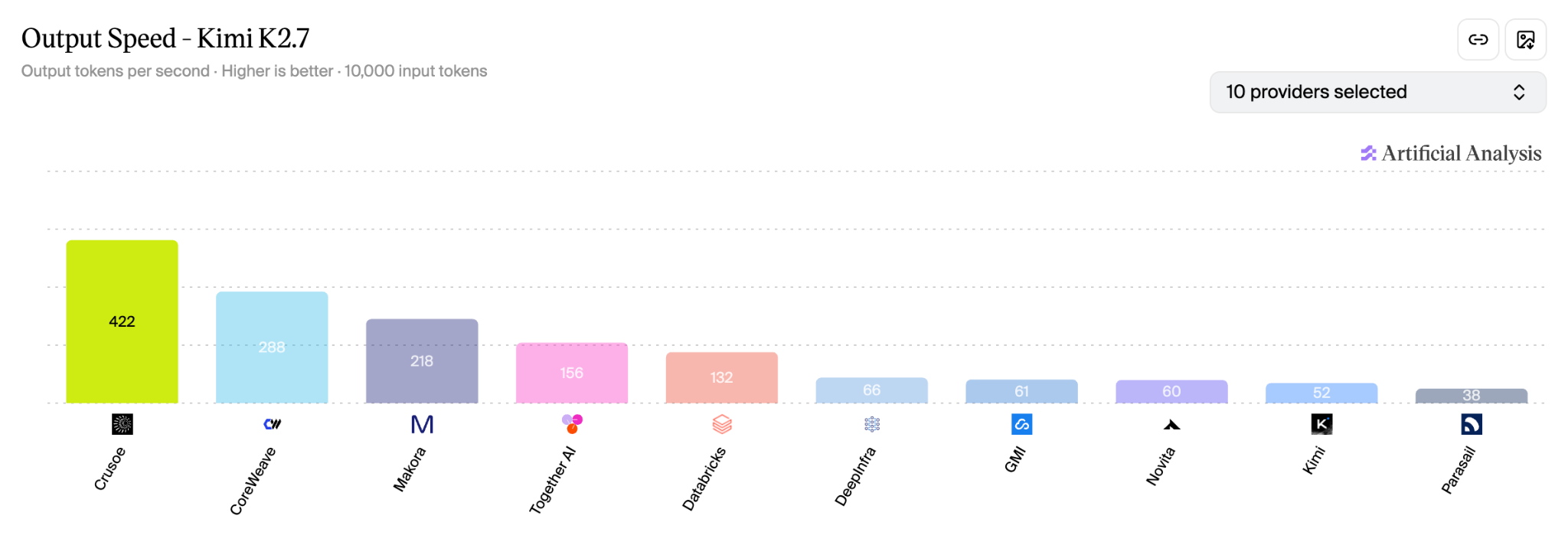
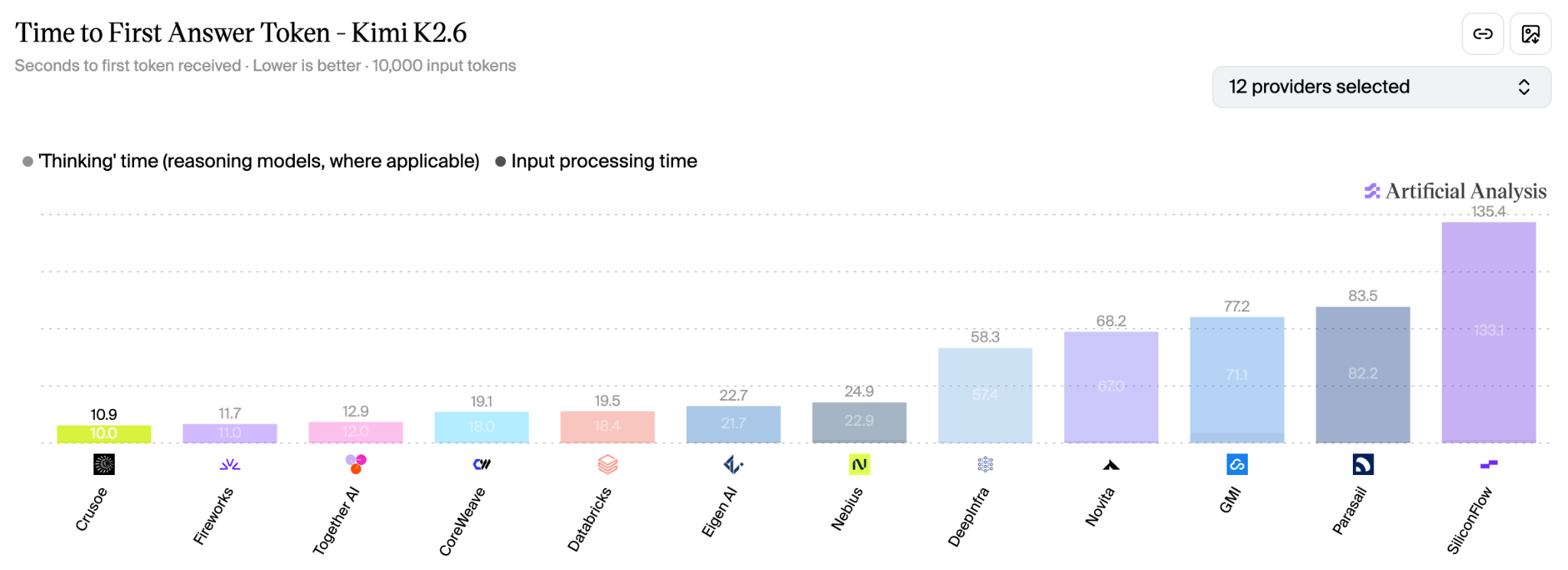
In June, our Kimi K2.6 and Kimi K2.7 deployments went live on Artificial Analysis. Both deployments achieved state-of-the-art performance, leading their respective provider leaderboards for output speed and response latency while running on Crusoe’s inference engine.
TL;DR
We built the fastest deployments of Kimi K2.6 and Kimi K2.7, reaching 430+ output tokens per second on Crusoe’s inference engine.
Getting there required optimizations across the full inference stack, including custom kernel-level improvements, high-quality quantization, a purpose-trained speculative decoding model, and disaggregated serving.
Why Kimi?
First and foremost, Kimi is already used by many of our customers running on Crusoe Managed Inference. Optimizing it was therefore a natural choice. Since these models power important production workloads on our platform, we wanted to push their performance as far as possible, focusing not only on benchmark results, but also on the latency and throughput that matter in real applications.
Beyond customer demand, the Kimi family has quickly become one of the strongest open model families for coding and agentic workloads.
Kimi K2.6 is a native multimodal agentic model built for long-horizon coding, autonomous execution, tool use, and complex workflows. Kimi K2.7 builds on these capabilities with a stronger focus on end-to-end software engineering, improved instruction following over long contexts, and more efficient reasoning.
These capabilities make Kimi especially relevant for production workloads, where models need to do more than generate good answers. They need to operate tools, maintain context across long-running tasks, work with real codebases, and reliably complete multi-step workflows.
Beyond standard inference optimizations
Reaching these decode speeds required more than applying standard techniques such as NVFP4 quantization and using an off-the-shelf speculative decoding drafter.
We profiled and optimized several layers of the serving stack, focusing on the areas that had the greatest impact on real Kimi workloads (agentics).
The three core techniques behind the result were:
Custom kernel optimization
Through rigorous profiling, we identified a decode kernel that was operating suboptimally for specific Kimi workload shapes.
We developed a custom optimization for this path, reducing its overhead and improving GPU utilization during decoding. This change alone added approximately 40 output tokens per second.
At the speeds we were already reaching, improvements of this size do not come from a single configuration change. They require profiling the model at the kernel level, identifying workload-specific bottlenecks, and optimizing the exact execution paths that matter during generation.
A purpose-trained draft model
Speculative decoding performance depends heavily on the quality of the draft model. A generic drafter can improve speed, but its value is limited when acceptance rates fall across different domains, languages, or reasoning patterns.
Using our internal training infrastructure, we trained a custom draft model that achieves state-of-the-art acceptance lengths across a broad mixture of workloads, including coding, reasoning, multilingual requests, and general agentic tasks.
A major part of this work was improving the training mixture. We developed a technique for identifying domains and examples where the drafter struggled, mining challenging samples from those areas, and bootstrapping them back into training.
Disaggregated serving
Prefill and decode have different compute and memory characteristics, so we place them on separate worker pools and tune each phase independently. Prefill workers are optimized for high-throughput prompt processing and KV-cache generation, while decode workers are configured for memory-bandwidth efficiency and sustained token generation.
This separation prevents prefill requests from interfering with decode ones, making decode speed more smooth and less fluctuating. It also lets us scale the prefill-to-decode ratio based on prompt lengths, output lengths, and concurrency, improving throughput at higher batch sizes while keeping time to first token low and helping us meet customer latency and availability SLAs under changing traffic patterns.
Closing thoughts
Reaching 430+ output tokens per second required improvements across the full inference stack, from custom kernels and quantization to speculative decoding and serving architecture. No single optimization was responsible for the result. The performance came from combining multiple techniques and tuning them around the specific characteristics of Kimi workloads.
These optimizations are not only useful for benchmark performance. They improve the latency, throughput, and predictability of the production deployments used by our customers, helping us support demanding workloads while meeting their SLAs.
Try managed inference in Crusoe Intelligence Foundry. Sign up to get started.

