From the rack to ready: How Crusoe Provisioner gets every node to production
Crusoe Provisioner replaced a 30% MAAS success rate with 98.5% first-pass provisioning on a 741-node NVIDIA HGX B200 deployment using a manifest-driven idempotent design and ephemeral OS environment.



Every GPU node that joins Crusoe's fleet has to go from bare metal to a fully configured hypervisor: correct firmware, correct OS, correct configuration, every time. Delivering reliable compute at scale requires a provisioning system that can do this consistently. Crusoe Provisioner is ours. This post explains how it works, why the design decisions matter, and what the results look like from our most recent large-scale NVIDIA HGX B200 deployment.
The problem with the old approach
For years, Crusoe relied on MAAS (Metal as a Service) to provision bare-metal nodes. MAAS is a broadly capable tool, but it wasn't designed for the demands of a GPU cloud at scale. Its provisioning model is stateless: it runs a sequence of steps, and if something fails midway (a firmware update takes too long, a network hiccup interrupts a download, a BIOS setting gets applied in the wrong order), the whole run fails and you start over. Every retry is a full re-run.
At a small scale, this is manageable. At the scale we operate today, it creates compounding problems. Across all GPU SKUs in our fleet, MAAS delivered a node provisioning success rate of approximately 30%, meaning nearly 7 out of 10 provisioning attempts required human intervention, retries, or both. GPU nodes have more firmware components than commodity servers, stricter configuration requirements, and longer provisioning times.
Crusoe Provisioner was built to fix this.
What does Provisioner do?
At its core, Provisioner is an idempotent, manifest-driven provisioning system. Every node SKU has a manifest: a YAML file that defines exactly which firmware versions should be running on each component, what BIOS settings should be applied, and what OS image should be installed. When Provisioner runs, it reconciles the node to that manifest. When a component's firmware (BMC, BIOS, HGX, NIC, DPU, or NVMe) is older than the manifest specifies, Provisioner upgrades it to the target version and reboots if the phase requires it. Upgrading firmware across this many components, in the right order, is the bulk of what a run actually does.
What keeps that safe at scale is idempotency: Provisioner only takes action where there's a delta. If the BMC firmware is already at the target version, that step is skipped. If the BIOS settings are already correct, they're not reapplied. So a partial failure is no longer a reason to start over — it's information about exactly which step needs to be retried, and re-running on an already-provisioned node is safe and fast.
How a provisioning run works
When a node is ready to be provisioned, it's validated against our DCIM for correct MAC address registration, network reachability, and BMC accessibility before entering the pipeline. Nodes that don't pass this gate are surfaced for remediation before they consume provisioner capacity. From there, the run follows a structured 14-step pipeline:
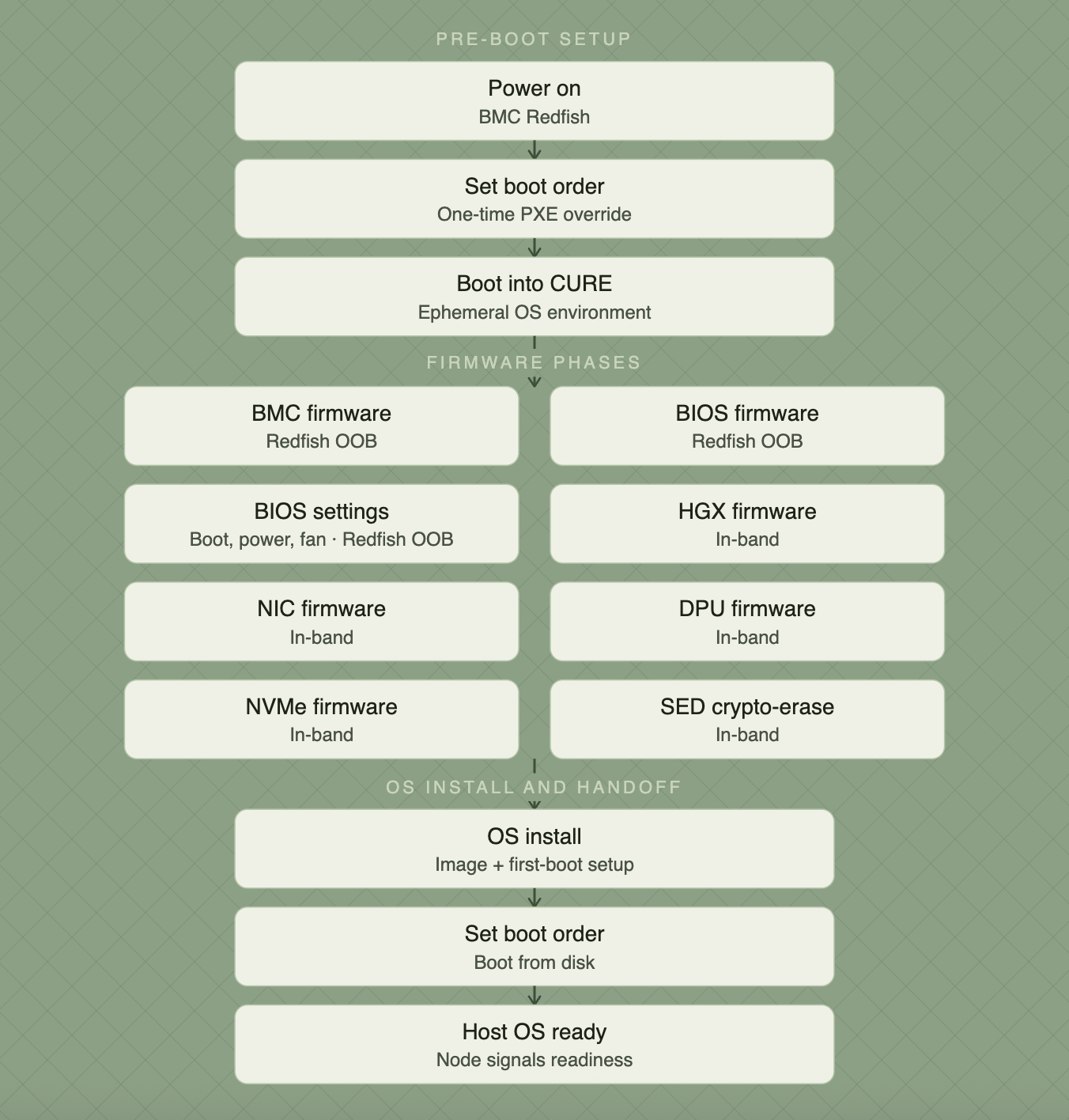
Pre-boot setup
- powering_on: Provisioner issues a power-on via BMC Redfish if the node isn't already running.
- set_boot_order #1: The BMC is instructed to boot once from PXE on the next power cycle. This is a one-time override; the default boot order (disk-first) is preserved for all subsequent boots.
- wait_for_cure: The node PXE-boots into CURE (Crusoe Ubuntu Runtime Environment), Crusoe's ephemeral OS environment. CURE is a lightweight ramdisk image that provides a controlled execution environment for all firmware and OS operations.
Firmware phases
- bmc: BMC firmware update out-of-band via Redfish
- bios: BIOS firmware update out-of-band via Redfish.
- bios_settings: BIOS configuration: boot order, power policy, fan profile.
- hgx: HGX firmware (NVIDIA GPU baseboard manager) update out-of-band via Redfish.
- nic: NIC firmware, applied in-band via host tools.
- dpu: BlueField-3 DPU firmware bundle in-band.
- nvme: NVMe SSD firmware in-band.
- sed_revert: TCG Opal PSID revert, a crypto-erase that is designed to wipe the previous tenant's data before the OS is installed.
OS install and handoff
- os_install: OS image installation and first-boot setup. Median: 2 minutes 14 seconds.
- set_boot_order #2: BMC boot order set to disk, so the node boots into the freshly installed OS.
- wait_for_host_os: Node boots into the installed host OS and signals readiness. Median: 8 minutes 30 seconds.
The full end-to-end time, when all firmware updates are required, is approximately 78 minutes. When a node's firmware is already at the golden versions defined in the manifest (increasingly common for nodes cycling through reprovision rather than first-time provisioning), steps 4 through 11 are skipped entirely. In those cases, the median end-to-end time drops to under 20 minutes.
What CURE provides
When a node PXE-boots into CURE (Crusoe Ubuntu Runtime Environment), it's running in a known-good, Crusoe-controlled in-memory environment with no dependency on whatever state the node's installed OS is in, or whether one exists at all. Firmware operations run in CURE before the OS is installed, which means:
- The OS is installed onto a clean, crypto-erased disk
- Firmware updates don't have to work around a running production OS
- The same environment is used whether a node is being provisioned for the first time or reprovisioned after repair
CURE is also used for field diagnostics. When a node needs hardware validation before or after an RMA, it can be booted into CURE's diagnostic mode without touching the host OS or requiring the node to be in any particular production state.
The results
In our most recent large-scale NVIDIA HGX B200 deployment, Provisioner brought 730 out of 741 nodes online successfully: a 98.5% success rate. The 11 that didn't make it on the first pass had real hardware issues, including NVMe drives returning unexpected errors, nodes with NVSwitch topology mismatches, and BMC network configuration failures. These aren't provisioning system failures; they're hardware signals that something needs attention before a node enters the fleet.
Compare that to MAAS at 30% across its full history of GPU SKU deployments. The delta isn't primarily about code quality. It's about the design. Idempotency means failures are isolated and recoverable. A manifest means the target state is always explicit and checkable. CURE as an execution environment means firmware operations run in a controlled context that doesn't depend on the host OS being in any particular state.
Built to provision in parallel
Nothing about a run is serial across nodes. Each node's run is fully independent, with its own manifest, its own executor, and its own BMC connection, so Provisioner brings up an entire rack, row, or deployment at once rather than one node at a time. The service itself is stateless and scales out: each instance runs hundreds of jobs concurrently, and total capacity grows linearly by adding instances. When an instance is at capacity it rejects new work immediately instead of queuing, so the client simply retries against another instance and throughput degrades gracefully under load rather than collapsing.
This is what lets a 741-node deployment finish on a deployment timeline rather than a per-node one. The wall-clock time to bring up a large batch is far closer to the time for a single node than to the sum of all of them.
The idempotency design in practice
The manifest-driven approach has a practical consequence that's easy to underestimate: re-running Provisioner is safe. This matters most at the two moments that disrupt production fleet operations.
The first is post-repair. When a node comes back from a GPU swap, a drive replacement, or a NIC failure, Provisioner can be re-run without risk. Steps that don't need to change are skipped. Steps that do need to change are applied. The node reaches the correct state without manual intervention to determine what changed.
The second is mid-run failure. When a provisioning run fails partway through (say, a network blip causes a firmware download to fail at step 10), the next run picks up from the remaining delta rather than starting over from step 1. What would have been a full 78-minute retry becomes a targeted recovery.
Reboots are expected, not failures
A full firmware run reboots the node five or six times: a BMC reset, host reboots after BIOS and HGX, NIC-level resets, and a final boot into the installed OS. Each one is a window where the node-agent executor disappears as it runs on a RAM-only CURE image which doesn’t require a stable network endpoint, and every reboot tears down its connection to the provisioner mid-job.
Provisioner is built around this. When a node reboots, the provisioner waits for it to come back, re-establishes the connection, and probes the executor for its current state before deciding what to do. If the executor came back up in a fresh CURE environment waiting for instructions, the provisioner resends the manifest along with resume state, the phase it had reached and how many times it has resumed, so work continues from where it stopped rather than from phase one. If the executor is still mid-phase, the provisioner simply re-attaches to its event stream without restarting it.
It also distinguishes a planned reboot from an unexpected disconnect. A dropped connection isn't assumed to be a dead node: a transient network blip, like a NIC driver reset or a middlebox closing the TCP stream, gets its own recovery budget, separate from the budget for genuine phase failures. A momentary glitch doesn't burn a node's retry allowance or fail an otherwise healthy run. Both paths are bounded and instrumented, so a node that truly can't recover is surfaced for attention rather than retried forever.
The practical effect: the roughly 35 minutes of reboots in a typical run are part of the expected flow, not 35 minutes of fragility. Designing for the node to disappear and reappear is what makes unattended, fleet-scale provisioning possible.
Observability for a node that keeps disappearing
Those reboots create a second-order problem: how do you observe a machine that has no persistent disk, no stable network identity, and vanishes every few minutes? The usual answer, a logging agent on the host that ships telemetry to a collector, does not apply. There is no host OS yet, nothing to persist to, and no endpoint that survives the next reboot.
Provisioner solves this by inverting where observability lives. The node never talks to a telemetry backend directly. The executor emits its logs and metrics over the same gRPC channel it already uses to coordinate with the provisioner, and the provisioner, which is long-lived and stably addressed, becomes the durable vantage point for everything happening on the node. It re-logs each event into its own pipeline and records the node's metrics into its own registry, so a machine that keeps losing its state still produces one continuous, structured timeline across every phase and every reboot. That same stream drives an engineer's terminal live during a run and lands in the same queryable store, tagged with the same provision and node identifiers, whether the run happened in a datacenter or on a laptop.
The broader point is that control and observability share one path. The channel that orchestrates the work is the channel that reports on it, so telemetry has the same lifecycle as the job itself: no separate agent to install, no extra endpoint to fail, and nothing to reconcile after the run is over.
Auditing without changing anything
Because the manifest is the declared desired state and every component is independently checkable, Provisioner can answer "what would change?" without changing anything. At its lightest, it compares what's on the node against the manifest and reports the deltas, which firmware versions and BIOS settings match the manifest and which have drifted, without downloading firmware or modifying the node. It's a quick check: point it at a node and get back a per-component matched/drifted summary in seconds.
When you need more confidence before committing to a real run, Provisioner can go further and download and verify every firmware artifact while still comparing versions, exercising the full pre-flight path but stopping short of applying updates or installing the OS. That answers a stronger question: is this node ready for provision, and are all the artifacts valid?
This runs on the same version-comparison engine that drives idempotency, so a check reflects exactly what a real run would do. It also works in direct mode against a device's BMC, which makes it useful for spot-checking DPUs and other Redfish-managed hardware without booting anything.
One pattern, more than provisioning
Provisioning is the first application of this architecture, but it isn't the only one. Strip the system to its essentials and you're left with three reusable ideas: a manifest that declares a desired end state, an ephemeral OS that gives every node a clean and controlled place to do work, and an autonomous on-node agent that executes against the manifest and reports per-component results. None of those are specific to just provisioning.
The most natural next use is hardware validation. Instead of a manifest that lists firmware versions, you write one that lists the tests a node must pass — GPU stress, memory, storage, NVLink and InfiniBand, thermal behavior under sustained load — boot the node into an ephemeral test environment, and let it run the suite autonomously. Because nothing external drives the run (no SSH, no VMs, no agent pre-installed on a production OS), a failure is unambiguous: it's the hardware, not the network or the orchestration layer. The result is a per-subcomponent verdict that names exactly what failed (GPU 3, NIC 0, NVMe 2), the same way provisioning reports exactly which firmware component drifted.
This matters because the failures that hurt most are marginal: hardware that enumerates fine and passes light checks but degrades under the sustained stress of real training. Catching those before a node reaches a customer is its own discipline, and the manifest-plus-ephemeral-OS model is a strong foundation for it; SKU-specific test suites with explicit pass/fail thresholds, the same artifact server and observability, and the same "re-running is always safe" guarantee. Validation here is even simpler than provisioning: a single boot, no reboots, no phases, just a linear run of tests. The same system that brings a node up can also prove it's worthy of production before it ever gets there.
What this means in practice
Speed of deployment is one of the less visible constraints on AI infrastructure. Customers waiting on capacity don't just need hardware to exist; they need it configured, validated, and ready. A low first-pass provisioning rate doesn't just create engineering toil, it directly delays when capacity reaches customers. And the same manifest-driven, ephemeral-OS approach that configures a node can also validate it: the system that brings a datacenter online quickly is the one that proves each node is production-worthy before handoff and keeps the fleet healthy afterward.
As AI workloads grow from dozens to thousands of GPUs, the infrastructure underneath has to scale with the same reliability. That means new sites come online on schedule, clusters expand without provisioning backlogs, and marginal hardware gets caught before it ever reaches a customer or disrupts a running job. Crusoe builds the systems that make that possible. That's what it means to be infrastructure customers can grow on.
Explore Crusoe Cloud's GPU offerings, or talk to our team about the infrastructure your workloads need.