
The Crusoe Cloud Journey: Evolution of the Edge
By Raghav Bhargava, Director of Networking Engineering at Crusoe
In Part I of our Crusoe Cloud journey, we laid out our founding principle to align technological progress with climate impact by building an energy-first neocloud. We then dove into the core problem: why traditional networks falter under AI’s demands, and our five guiding design principles for an AI-first network. In Part II, we pulled back the curtain on the heart of our infrastructure, detailing the strategic engineering behind the Crusoe backbone network — an architecture crafted for immense scale, resilience, and intelligent routing.
Today, we complete the picture. While a robust backbone is crucial, the true power of AI often lies in its proximity to the user. This final installment explores the evolution of the edge and how Crusoe is extending high-performance AI compute capabilities closer to where data is generated and consumed, further optimizing performance and efficiency for our ambitious builders.
The Imperative of the Edge
Since the launch of Crusoe Cloud, we’ve witnessed a monumental surge in internet traffic from our customers and hyperscalers alike. What began with gigabits of internet circuits in early 2023 quickly escalated. As our data centers expanded and customer traffic grew exponentially, it became abundantly clear: we needed a sophisticated, strategic approach for the network edge; one capable of delivering terabits of internet capacity through seamlessly integrated transit providers. This isn't just about speed. It’s about reducing latency, enhancing user experience, and making AI feel truly instantaneous, no matter where our customers are.
To achieve this, we’ve meticulously established a formidable network footprint across North America and Europe. This aggressive expansion has seen us add hundreds of gigabits of internet connectivity with leading regional and global transit providers across our growing array of Points of Presence (PoPs). It’s about building a global compute fabric that’s as close to our customers as possible, delivering the power of AI where it’s needed most.
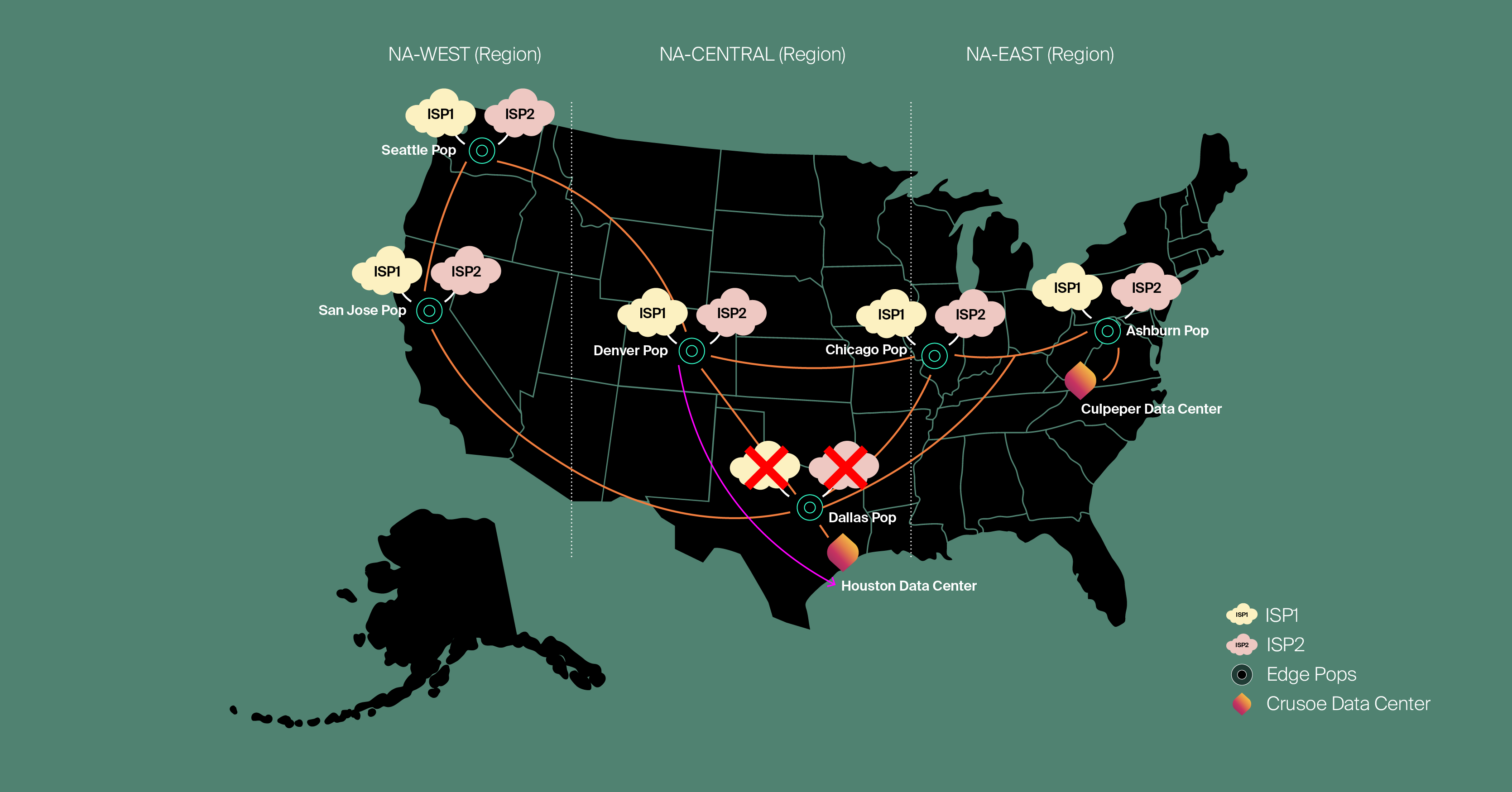
Routing Intelligence: The Metro Concept
To maximize efficiency and predictability at the edge, we’ve refined our routing policy design with several key objectives in mind:
Maximizing the efficient use of network resources
Enabling more predictable failure scenarios
Supporting more accurate capacity planning
Reducing operational complexity
Providing robust regional redundancy for Crusoe’s data centers
Our inventive design introduced the concept of a "metro.” By metro we mean segmenting regions into individual metropolitan areas. This intelligent approach ensures that Crusoe Cloud’s traffic largely remains local within each region, optimizing flow and reducing unnecessary hops. The core ideas behind the metro concept are simple yet profound:
Reduced Latency: Routing users to the nearest PoP within their metro area provides a superior, low-latency user experience.
Enhanced Redundancy: Incorporating multiple PoPs within some metros ensures continuous service, even if a single point encounters an issue.
Predictable Failure Domains: Treating each metro as its own isolated failure domain allows us to precisely reroute traffic by selectively withdrawing metro-specific prefixes from the internet, ensuring localized impact and rapid recovery.
Controlled Advertisements: Prefixes are contained within their respective metros or regions, with advertisements to the internet carefully limited to those areas based on context.
To underpin these sophisticated routing decisions, we meticulously updated our BGP communities. Prefixes are now tagged with their origin, and both internally and externally learned routes are assigned appropriate route types. Advertisements are dynamically controlled and summarized by their route scope (Metro, Region, Continent, or Global) allowing routers to apply special handling based on tags, which can also carry additional community attributes. This granular control is crucial for managing terabit-scale traffic with precision.
Unifying and Optimizing IP Transit for the Future
Until late 2023, Crusoe’s transit capacity, while robust, was unevenly distributed. We've tackled this head-on by standardizing IP transit capacity and meticulously designing our PoPs to ensure each location has ample capacity. This means that during an outage or Disaster Recovery Testing (DRT), we have sufficient capacity to reroute traffic seamlessly between metros, preserving customer performance.
We also faced the challenge of imbalanced ingress traffic from transit providers. To resolve this, we collaborated closely with our Tier-1 providers, implementing solutions that intelligently balance inbound traffic into our Autonomous System Number (ASN). Further, we redesigned our edge routing policies so that prefixes now exit our ASN via the transit provider with the shortest AS-PATH. In instances where multiple Tier-1 providers offer equal AS-PATH lengths, we leverage the BGP Multi-Exit Discriminator (MED) attribute to break the tie, ensuring optimal, lowest-latency paths for our customers. This commitment to detail is what sets an AI-first network apart.
Expanding Peering: Building Direct Connections
Up until Q1 2025, a significant portion of Crusoe Cloud’s traffic traversed transit providers. Recognizing the imperative for lower latency and cost-efficiency that direct peering offers, we began actively identifying key Autonomous Systems (ASNs) behind these transit providers in each metro, gathering data via NetFlow. Our ambitious goal: to develop a targeted list of ASNs for peering discussions by the end of Q3.
By the end of 2025, Crusoe will operate in nine cities across North America and Europe, supporting nine PoPs. This expansion will push our edge capacity well into the terabit range. During this rapid growth phase, we’ve already added hundreds of gigabits in transit and peering capacity, standardizing our transit footprint across the entire network. This direct peering strategy reduces network hops, lowers data transfer costs, and provides our customers with even faster, more predictable access to their AI workloads.
Always Building for What’s Next
Crusoe now handles hundreds of gigabits of traffic, expanding at an unprecedented rate. To keep pace, the Crusoe Networking Engineering team lives by the mantra: “build for scale.” This means more than just adding capacity; it involves continuously evolving our architecture and consistently planning for growth and operations at ten times our current scale.
We think two to three years ahead, ensuring we have the necessary tools, automation, and monitoring systems in place to support a network operating at ten times today’s capacity. This forward-thinking, resilient, and pioneering philosophy is applied uniformly across our entire network, whether at the data center, backbone, or edge level, ensuring Crusoe is always ready for what's next in the AI revolution.
Ready to experience a cloud built for the future of AI? Explore Crusoe Cloud today.


